DOI: 10.3389/fnagi.2021.635945
One-Liner
extracted lexicographic and syntactical features from ADReSS Challenge data and trained it on various models, with BERT performing the best.
Novelty
???????
Seems like results here are a strict subset of Zhu 2021. Same sets of dataprep of Antonsson 2021 but trained on a BERT now. Seem to do worse than Antonsson 2021 too.
Notable Methods
Essentially Antonsson 2021
- Also performed MMSE score regression.
Key Figs
Table 7 training result
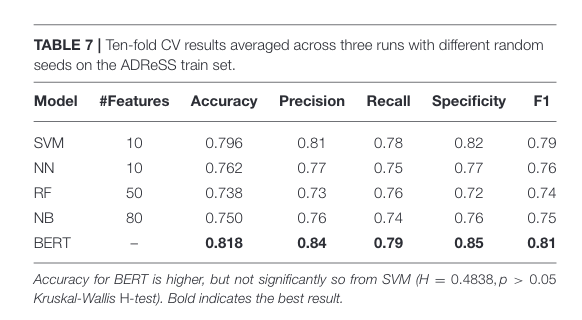
This figure shows us that the results attained by training on extracted feature is past the state-of-the-art at the time.
Table 4

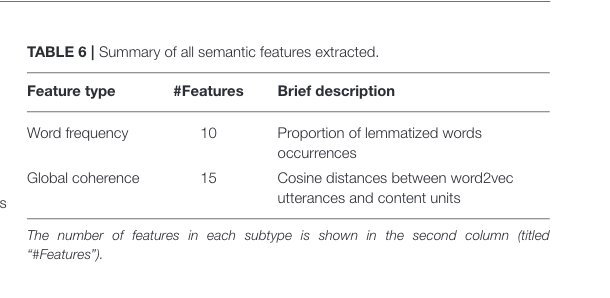
These tables tells us the feature extracted