Background
recall AlphaZero
- Selection (UCB 1, or DTW, etc.)
- Expansion (generate possible belief notes)
- Simulation (if its a brand new node, Rollout, etc.)
- Backpropegation (backpropegate your values up)
Key Idea
Remove the need for heuristics for MCTS—removing inductive bias
Approach
We keep the ol’ neural network:
\begin{equation} f_{\theta}(b_{t}) = (p_{t}, v_{t}) \end{equation}
Policy Evaluation
Do \(n\) episodes of MCTS, then use cross entropy to improve \(f\)
Ground truth policy
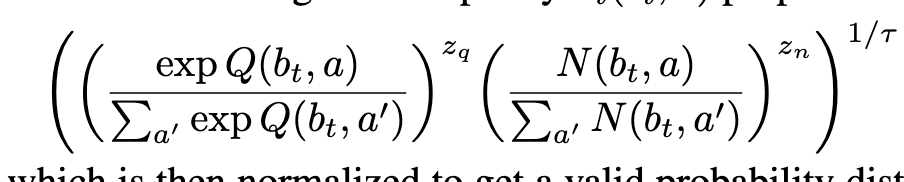
Action Selection
Uses Double Progressive Widening
Importantly, no need to use a heuristic (or worst yet random Rollouts) for action selection.
