DOI: 10.3389/fnagi.2021.623607
One-Liner
Trained a bimodal model on speech/text with GRU on speech and CNN-LSTM on text.
Novelty
- A post-2019 NLP paper that doesn’t use transformers! (so
faster(they used CNN-LSTM) lighter easier) - “Our work sheds light on why the accuracy of these models drops to 72.92% on the ADReSS dataset, whereas, they gave state of the art results on the DementiaBank dataset.”
Notable Methods
Bi-Modal audio and transcript processing vis a vi Shah 2021, but with a CNN-LSTM and GRU on the other side.
Key Figs
Figure 1: Proposed Architecture
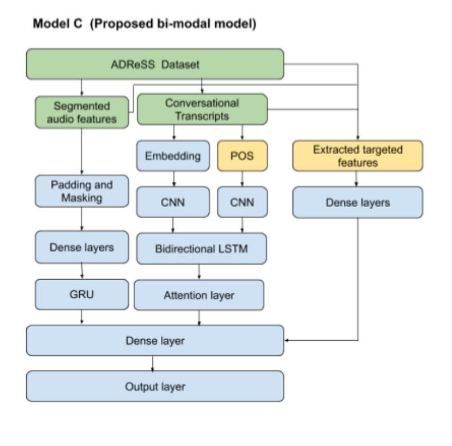
The figure highlights the authors’ proposed architecture
Figure 2: confusion matrix
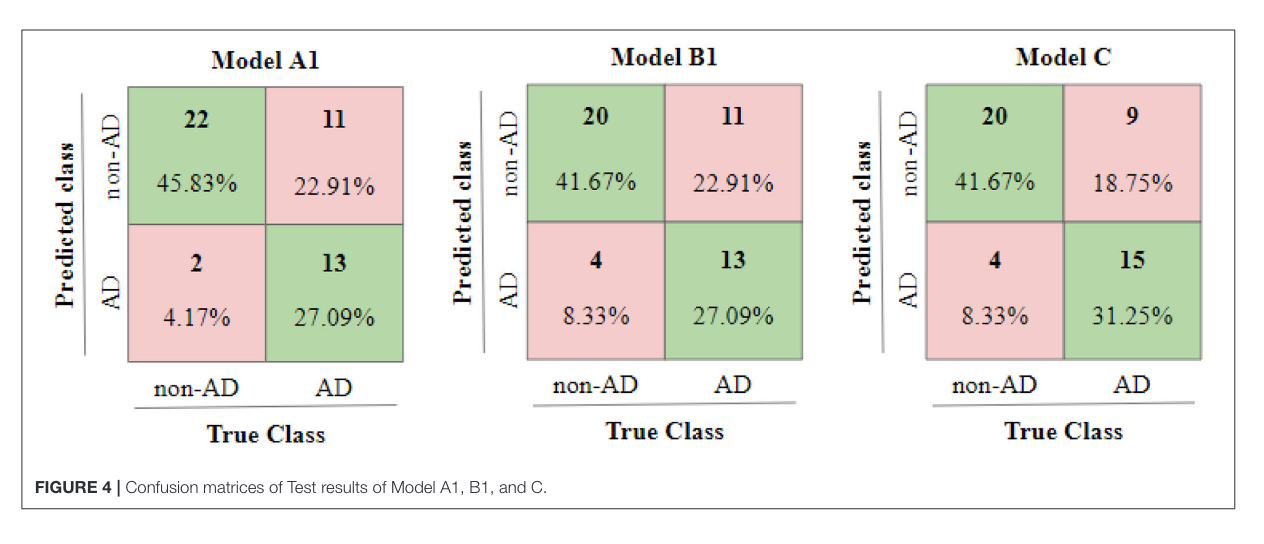
In addition to validating prior work by Karlekar 2018 and Di Palo 2019, proposed model C and got accuracy of \(73.92\%\).