Happy Monday friends.
The deliverable of the week was to make the a ASR model for Batchalign. Essentially, most copies of Whisper is pretty bad at Language Sample Analysis (LSA), because they mostly don’t work in terms trying to actually capture the things that people doing LSA want to capture (disfluencies, stuttering, etc.). OpenAI even acknowledged in the paper that they filtered out the disfluencies from their gold transcript to prevent Whisper from writing down too much of them.
And so… We roll up our sleeves and do it ourselves.
A Large Language Model
I didn’t want to perform Low-Rank Approximation (LoRA) to heavily when training this model. Folks fine tuning LLaMA will note that the preferred parameters were essentially asked the user to make the model matricies Rank 8, across the entire model.
When trying this in earlier experiments, we failed dramatically as the LoRA’d model failed to converge when we hit any smaller rank below 10. However, if we tried to, say, do it above 10, I would OOM.
I will note: its not like we don’t have compute. For this project, I fortunately am able to provision any number of V100 32GB as I see reasonable to train this model. Nevertheless, a lovey dovey parameter heavy 1.5 Billion parameter model is still a sight to behold (and cram into one such GPUs).
Hence, the most important impetus for making this work without aggressive LoRA and degraded performance is some kind of model parallel training scheme.
One Model, Multiple Cards


Alr then.
After investigation, DeepSpeed seemed pretty promising for a few reasons. The third iteration of its algorithm (Zero-3) has three different main offerings:
- Model parameter sharding (sharding the weights of the model across devices)
- Optimizer state sharding
- Model/Parameter state offload
The last one caught my eye. Essentially, as long as your chip has the ability to perform a single forward pass, it can train a model under Zero-3. This is because the system is designed, on request, to offload the weights of your model into CPU or NVMe if you want—and only pull it into the main device for the actual step of forward/backwards passes.
The thing about DeepSpeed is that its configured in a very hapazard way, and once you DeepSpeed onto your training script you can’t really go back: it expects model parallel training, in the way you configured it, always, based on the contents to the training script.
Huggingface Accelerate to the rescue! The system is essentially a generic hypervisation framework. It is designed to accelerate model training using any framework you’d like: CPU data parallel, GPU data parallel, DeepSpeed model parallel, and so on—with a single configuration file.
With minimal change to your training script, your actual acceleration scheme travels with a configuration file on device. Meaning, running the same script on different devices configured with Accelerate will use the best settings for that device; including the correct number of cards, accelerators, etc.
Pedal to the Metal
As usual, despite how good all of this stuff sounds, getting it all to glue together was a hot mess.
Accelerate
Let’s start with Accelerate. The actual process of integrating Accelerate into your training script is pretty straightforward:
accelerator = Accelerator()
DEVICE = accelerator.device
model, optim, dataloader, val_dataloader = accelerator.prepare(model, optim, dataloader, val_dataloader)
and then, in your training loop, change
- loss.backward()
+ accelerator.backward(loss)
and finally, whenever you need to access a value in CPU, change
- loss = torch.mean(loss.cpu())
+ loss = torch.mean(accelerator.gather(loss))
That’s honestly about it in terms of making accelerate work.
DeepSpeed Shenanigans
DeepSpeed is a great tool to accelerate model training, but the damned thing is so janky to actually get started because of various device integration issues.
There’s this excellent thread on Reddit with people winging about the various things that DeepSpeed is broken about. To actually get it to actually work on my end…
- deep breath. pray to deity of your choice, etc. and Install Conda
pip install deepspeedconda install openmpipip install mpi4py(if this fails,env LD_LIBRARY_PATH=/your/conda/lib/path pip install --no-cache-dir mpi4py)
If you now ran DeepSpeed on a model, it likely will crash on a local random assert statement. To fix this, get ready:
find runtime/zero/partitioned_param_coordinator.py wherever your DeepSpeed code is, and:
- assert param.ds_status == ZeroParamStatus.AVAILABLE, param.ds_summary()
+ # assert param.ds_status == ZeroParamStatus.AVAILABLE, param.ds_summary()
comment the damned assertion out. Yup.
Oh, also, this https://github.com/huggingface/trl/pull/687 if you are running inference.
Accelerate Device Config
And now, onto the device configuration. If you are most normal people, you can just run:
accelerate config
answer the questions, and be done for configuring that device. However, as I was training on a SLURM device, I had no access to a tty. Hence, I had to configure the Accelerate device configuration myself.
To glue Accelerate and Deepspeed together, here was the config.
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 1
offload_optimizer_device: none
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 3
distributed_type: DEEPSPEED
fsdp_config: {}
downcast_bf16: 'no'
machine_rank: 0
mixed_precision: 'no'
num_machines: 1
num_processes: 3
use_cpu: false
Here are the highlights:
mixed_precision: 'no': FP16 doesn’t work if you do your own tensor creation within the train loop as I did though the Whisper models. Your DataLoader passed to your accelerator at the beginning of the script must return the exact tensors you put into the model if you want FP16.
offload_optimizer_device: none: offloading optimizer requires you to compile the PyTorch extension adam_cpu from DeepSpeed. I never got it to work on the training rig because it required CUDA headers (why? how? why is adam_cpu CUDA? no clue). Notably, optimizer SHARDING across GPUs still work, because that has nothing to do with offload.
zero_stage: 3: stage 1 is state sharding, 2 is optimizer sharding, 3 is optimizer AND parameter sharding.
num_processes: 3: for GPUs, num_processes is the number of GPUs Accelerate/DeepSpeed should use.
Friggin LoRA
In the sprit of not wasting too many monies, I still conceded and used LoRA. This was a fairly straightforward setup through Huggingface PEFT.
Here was my config:
peft_config = LoraConfig(inference_mode=False,
r=16,
target_modules=["q_proj", "v_proj", "out_proj"],
lora_alpha=32,
lora_dropout=0.1)
and the integration:
model = WhisperForConditionalGeneration.from_pretrained(f"{MODEL}")
+ model = get_peft_model(model, peft_config)
Simple as that. One protip: call model.train(); otherwise you will be hit with:
File "/jet/home/hliuk/.conda/envs/chat-whisper/lib/python3.10/site-packages/torch/nn/modules/conv.py", line 309, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: weight should have at least three dimensions
presumably because of some conflict with inference_mode setting the wrong .forward() paths.
On the machine, merge_and_unload never worked. Instead, I downloaded the LoRA weights (instead of the merged full weights) and then called that on my local machine.
Two highlights from the LoRA config:
r=16: we set the rank of the matrix into 16, because anything lower causes the model to stop converging. This still ended up needing 3 GPUs to actually cram fit.
lora_alpha=32: I saw somewhere that the LoRA weight scaling factor, which is lora_alpha/r, should always be larger that \(1\). Your mileage may vary.
["q_proj", "v_proj", "out_proj"]: it seems like many people are not a fan of LoRAing the key matricies—why? I don’t know. I’m following that convention here.
And so…
Two days, and much wandb later, we’ve got a model!
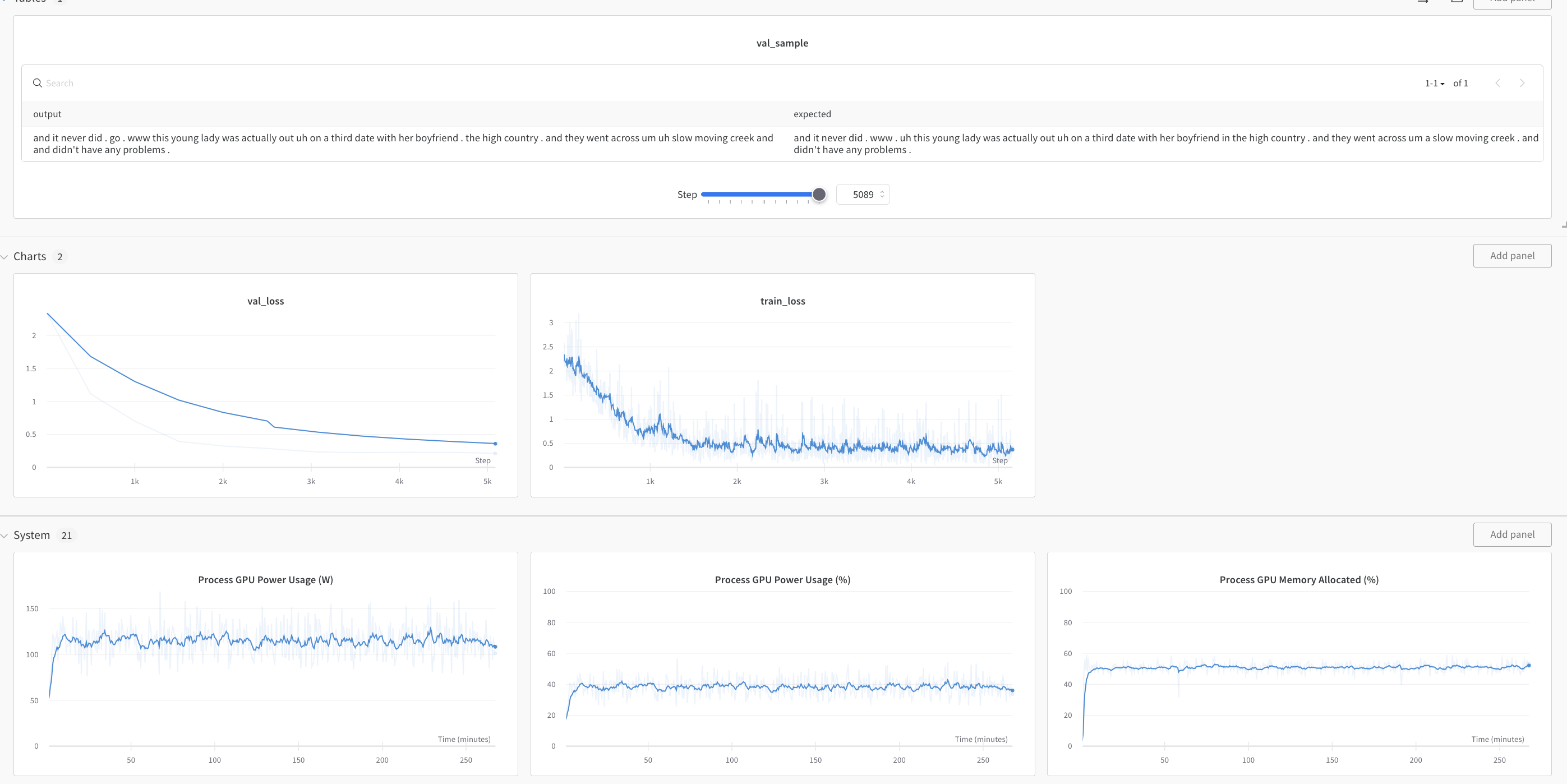
We could’ve pushed the GPU up a little by setting LoRA rank higher, but I found that if the memory is sitting at anything above a \(80\%\) ever, the system will eventually OOM.