DOI: 10.3389/fnagi.2021.642647
One-Liner
Combined bag-of-words on transcript + ADR on audio to various classifiers for AD; ablated BERT’s decesion space for attention to make more easy models in the future.
Novelty
- Pre-processed each of the two modalities before fusing it (late fusion)
- Archieved \(93.75\%\) accuracy on AD detection
- The data being forced-aligned and fed with late fusion allows one to see what sounds/words the BERT model was focusing on by just focusing on the attention on the words
Notable Methods
- Used classic cookie theft data
- bag of words to do ADR but for words
- multimodality but late fusion with one (hot-swappable) classifier
Key Figs
How they did it
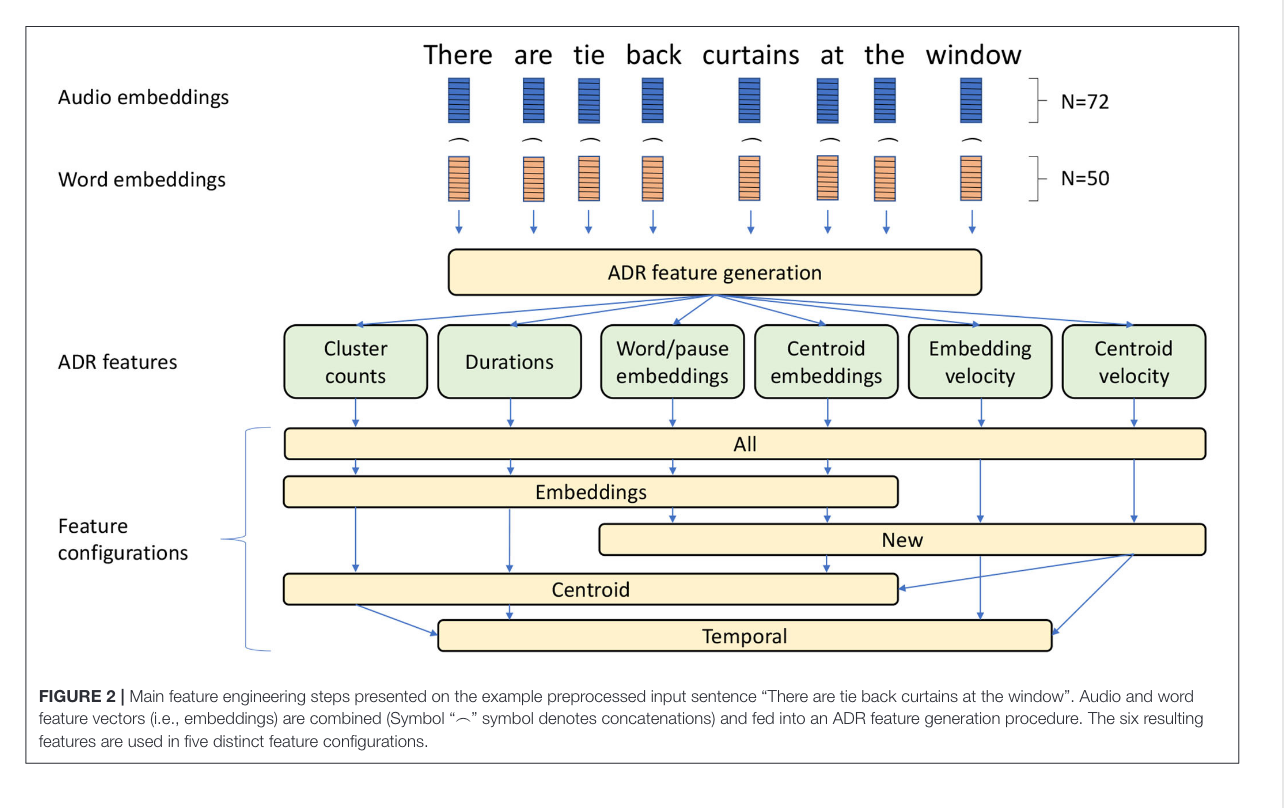
This is how the combined the forced aligned (:tada:) audio and transcript together.
Bertbelation
Ablated BERT results.
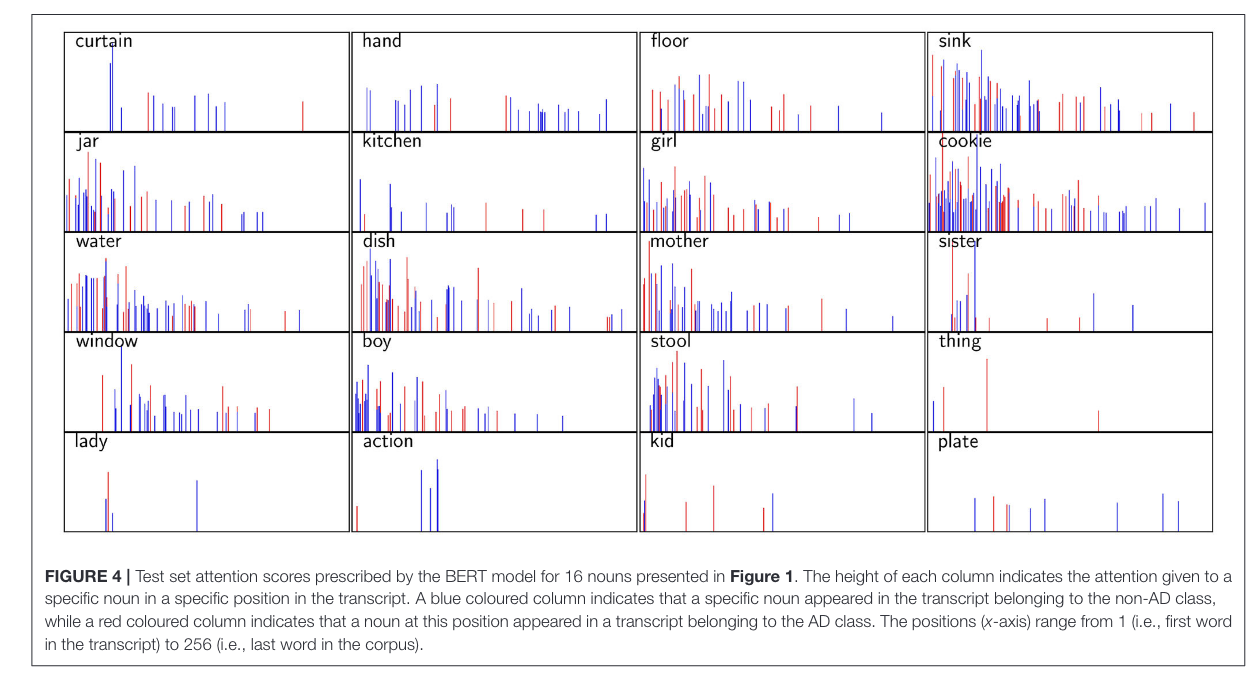
The model overall tends to focus on early parts of sentences. y is attention weight, x is position in sentence, blue is TD, red is AD.