Updates
- dropping dropout: https://proceedings.mlr.press/v202/geiping23a/geiping23a.pdf
- CAW-coref: revised! do we need more space for things such as a figure?
- stanza 1.9.0 staged! https://huggingface.co/stanfordnlp/stanza-en
Yay mend works!
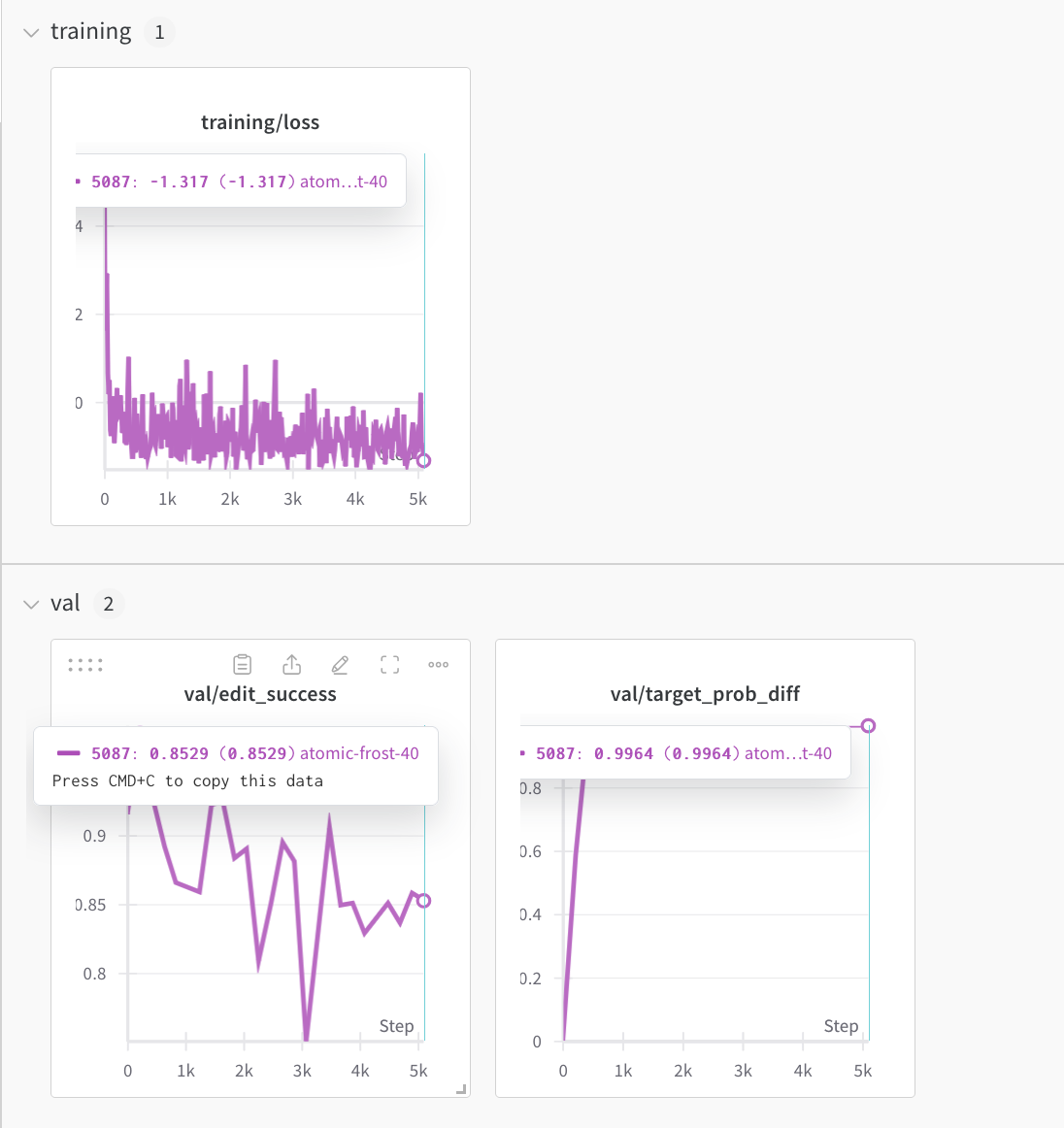
.mean() vs. .sum() for the dW maps?
PPL Isn’t the Only Possible Metric
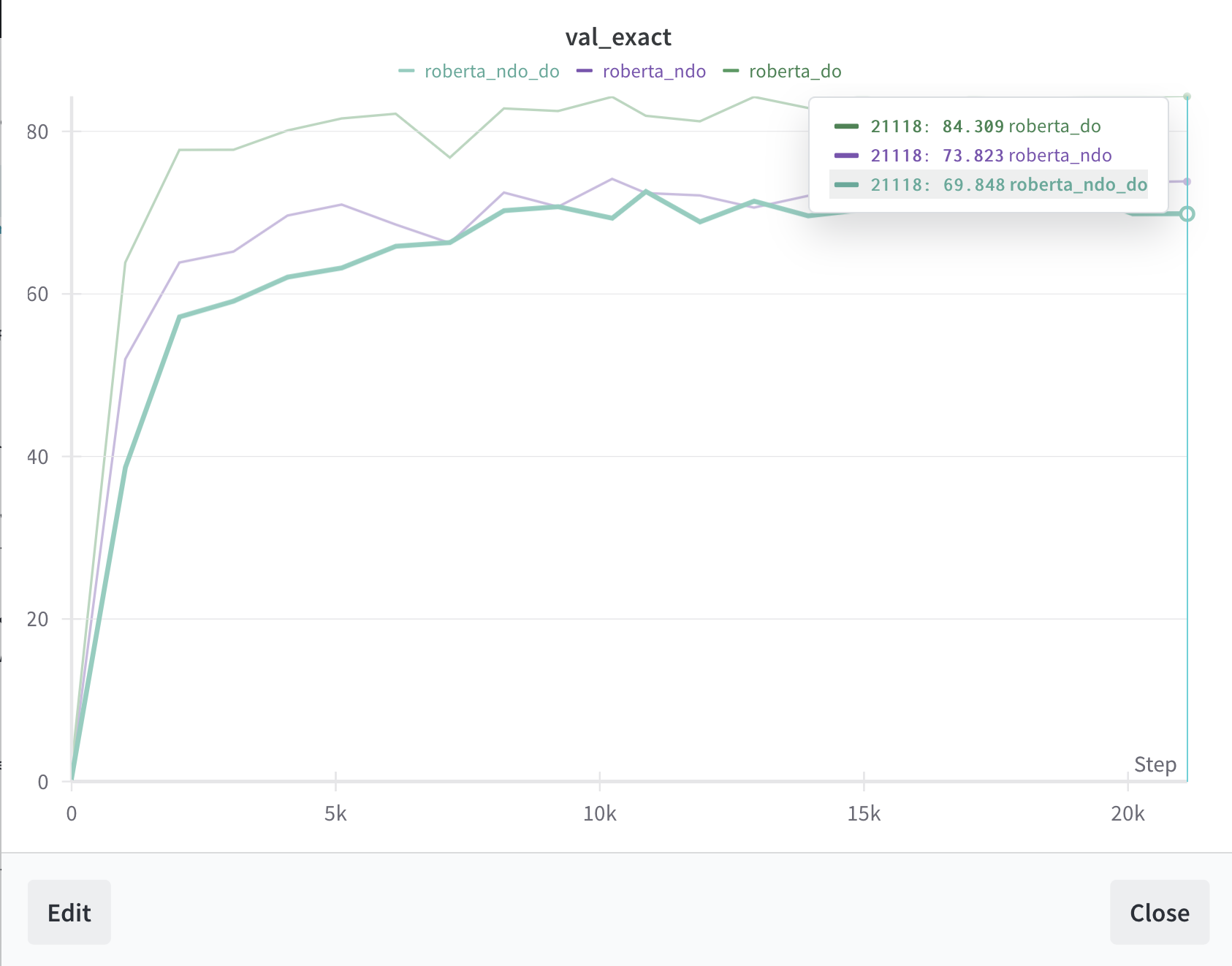
even if our model is better ppl, its worse at squad than Facebook (granted its been trained a lot less); will run with new pretraining model (expect that no dropout will be better (see paper above)).
Pretraining Updates (smaller Bert, which dataset?)
https://wandb.ai/jemoka/dropfree?nw=nwuserjemoka
Binary Masking with the Pretraining Above
Edit success
| Our Bert (No Dropout) | Our Bert (Dropout) | |
|---|---|---|
| edit success | 0.9709 | 0.9723 |
| edit localization | 0.8375 | 0.8452 |
| mean activations | 3853 | 22511 |
Yay! (more seriously)
Question
Paper Plan
Part 1: Skipping Dropout isn’t bad, and may even be good
- pretraining
- squad
Part 3: Emperics: Dropout Has Knowledge Storage Consiquences
- knowledge neurons
- integrated gradients
- binary masking
Part 4: Impact: look, editing is easier without dropout (no data yet)
consistency (this is weak, hence theory maybe helpful, or we can skip)
MEND (just worked yay!)
Finetune (echo to squad)
LoRA
slowly reduce ReFT update rank, see how edit success drops
(x verbs y)
- for each, train/(MEND infer) on 90%, test on the other 10%, see if it works
- “correct” to the {IID} example
Casual Interventions
shall we? simple exchange interaction? how does it work for a bert? does it fit into this story?
(ottowa captial <mask>) => (DC capital <mask>)