Define “granularity” as:
\begin{equation} G = \frac{d_{\text{ff}}}{d_{\text{expert}}} \end{equation}
at \(G=1\), we have a dense model; at \(G>1\), we have some kind of MoE.
Here are thy scaling laws:
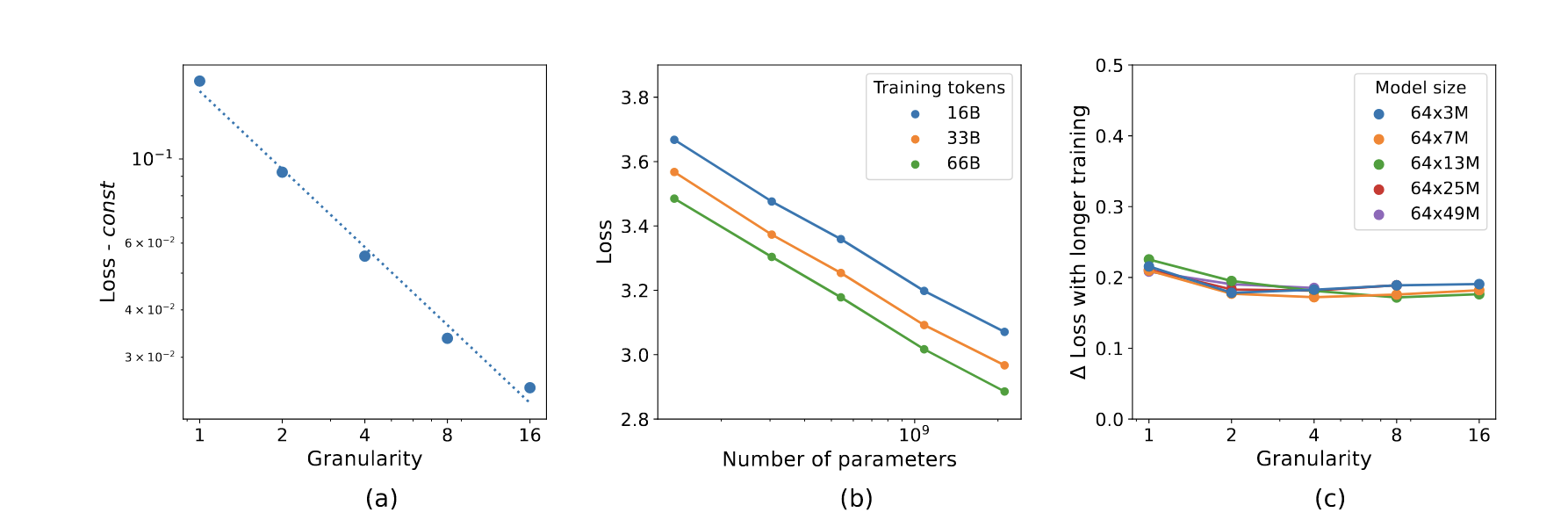
notice how its mostly linear! tiny experts yay!
Define “granularity” as:
\begin{equation} G = \frac{d_{\text{ff}}}{d_{\text{expert}}} \end{equation}
at \(G=1\), we have a dense model; at \(G>1\), we have some kind of MoE.
Here are thy scaling laws:
notice how its mostly linear! tiny experts yay!