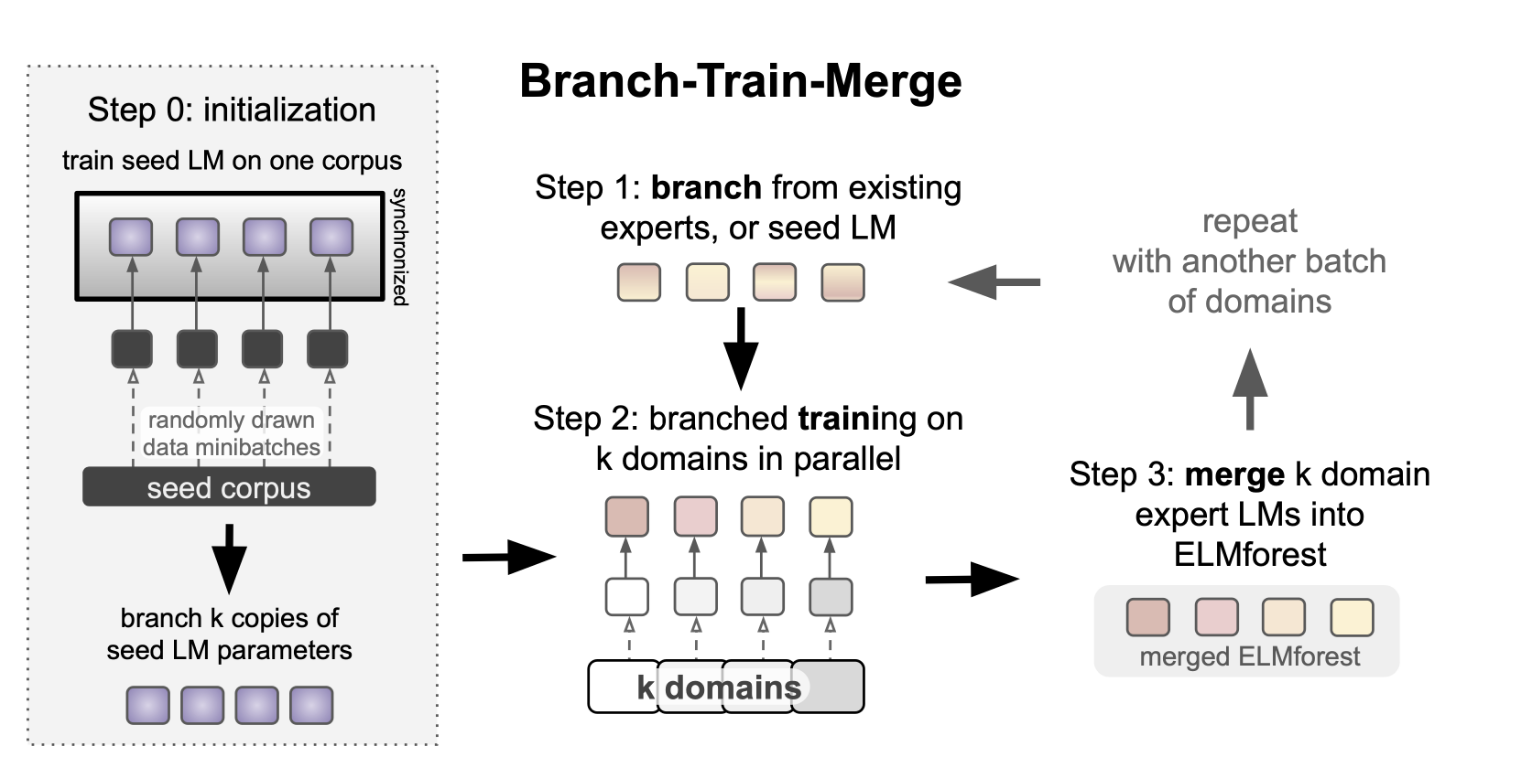
- weighted parameter average of the existing experts (or copy the new perts)
- training each expert independently
And then when inference we can use domain-conditioned averaging between the experts by computing:
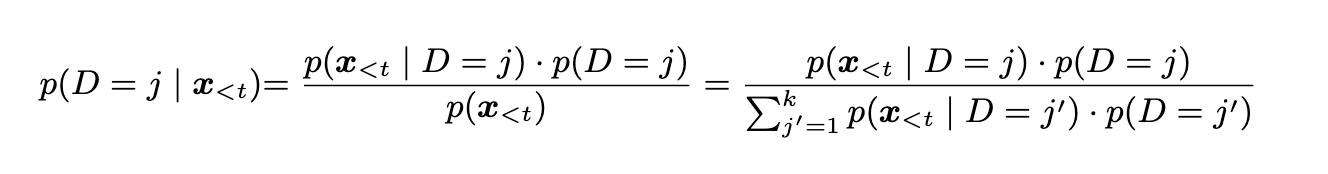
or by averaging the parameters of the experts.