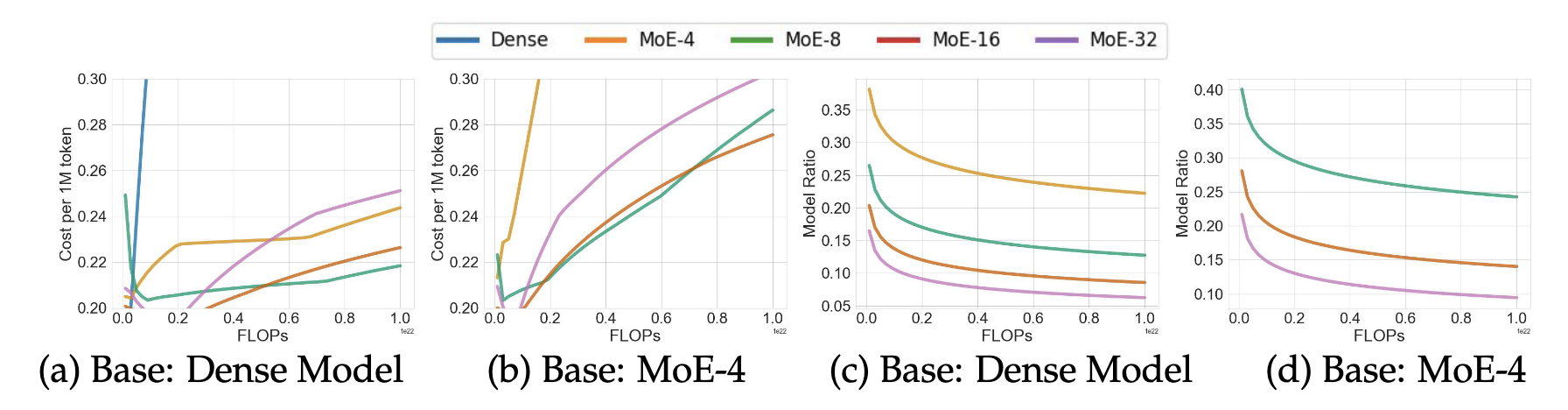
“the scaling law (Section 3) shows that more experts (larger E) result in a higher performance; on the other hand, more experts result in a larger inference cost (Section 4.2)”
How do we trade off cost of more experts (in terms of GPU-seconds or , for \(C_0\) being the cost for some per second GPU cost) and performance?
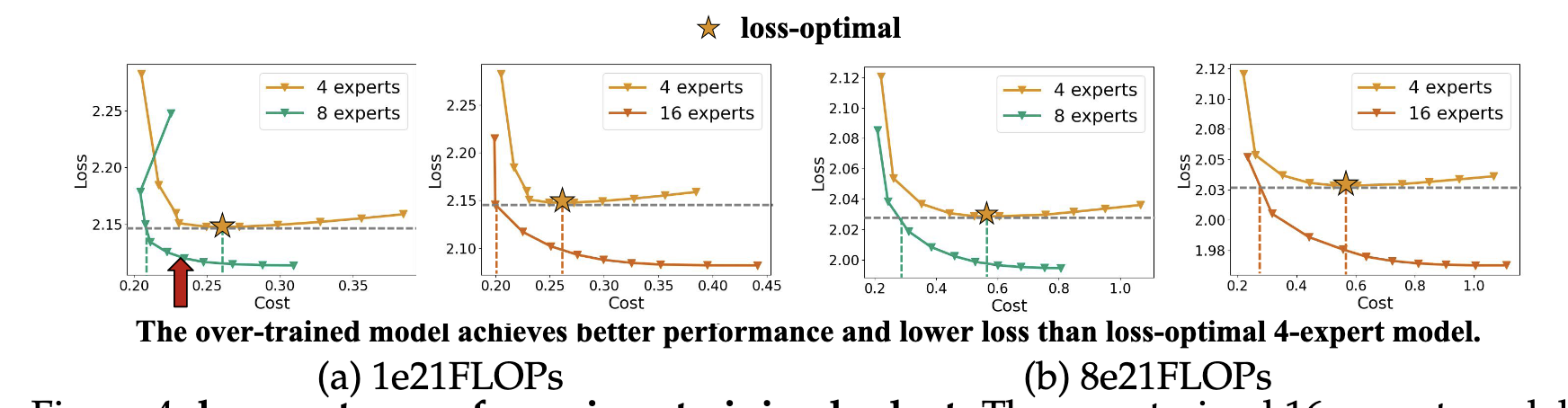
so, slight over-wraiting achieves better performance. Two findings:
- smaller bigger expert (4/8) is the most serving efficient, but costs more to train to the same loss
- with enough data, big (16/32) expert MoE could be smaller, and slight trianing can boost performance