We can think of a neural network as a roll-out of a system. For ReLU networks in particular, we can compute the exact reachable set!
Suppose we have the input set \(s_1\); let’s consider:
\begin{equation} z_1 = W_1 s_1 + b_1 \end{equation}
after one linear layer. We can then apply a nonlinear function to it. The beauty with ReLU nonlinearities is that we can split our network into one set per quadrant, and consider what ReLU will do to it.
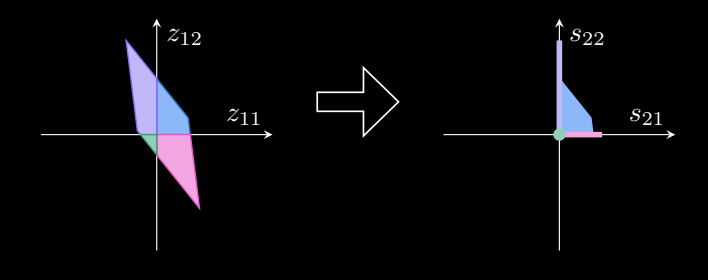
As you can see this blows up at high dimensions. Instead, we can try an overapproximation!
Pick a set of bounding vectors \(d\) (edges), and we want to pick a vector \(s\)
\begin{equation} \max_{s} d^{T} s_{d} \end{equation}
such that
- \(s_1 \in \mathcal{S}\)
- \(s_{d} = f_{n}\qty(s_{1})\)
such that each next step is a possible output for our network.