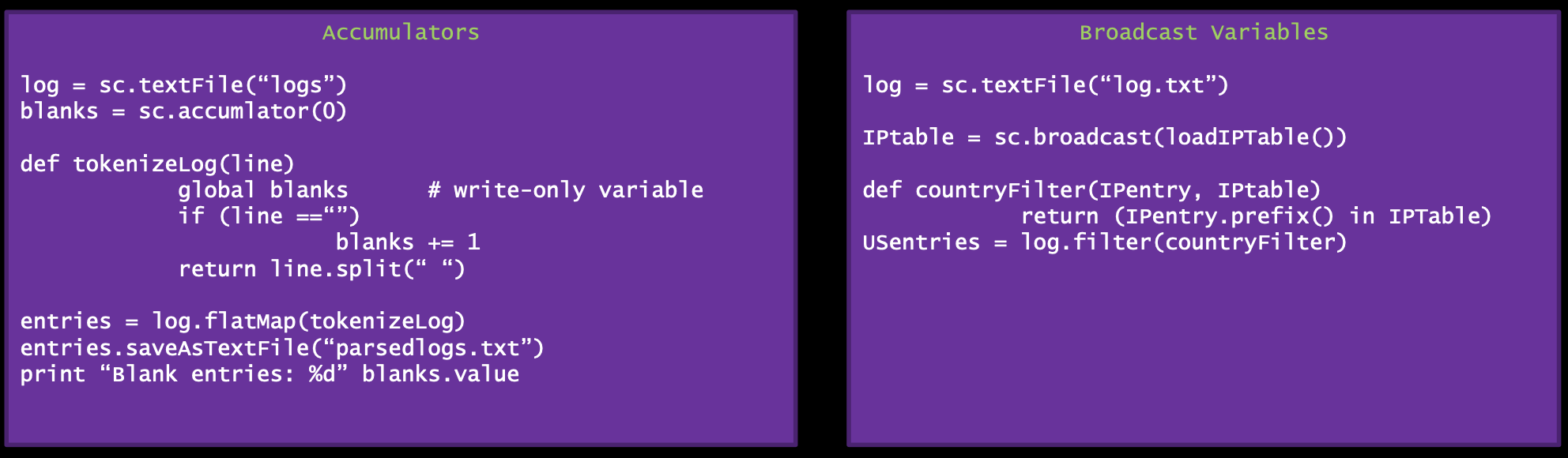
In the event your domain knowledge can help you make decisions about how spark load-balances or stripes data across worker nodes.
Persistence
“you should store this data in faster/slower memory”
MEMORY_ONLY, MEMORY_ONLY_SER, MEMORY_AND_DISK, MEMORY_AND_DISK_SER, DISK_ONLY
rdd.persist(StorageLevel.MEMORY_AND_DISK)
# ... do work ...
rdd.unpersist()
Parallel Programming