Background
Current deep-learning first approaches have shown promising results for the speech text diarization task. For ASR-independent diarization, specifically, two main methods appear as yielding fruitful conclusions:
Auditory feature extraction using deep learning to create a trained, fixed-size latent representation via Mel-frequency cepstral coefficients slices that came from any existing voice-activity detection (VAD) scheme ((Snyder et al. 2018)), where the features extracted with the neural network are later used with traditional clustering and Variational Bayes refinement ((Sell et al. 2018; Landini et al. 2022)) approaches to produce groups of diarized speakers
End-to-end neural approaches which takes temporally-dependent log-mel-frequency cepstrum and perform voice activity detection, speaker recognition, and diarization directly on the same neural network ((Fujita, Kanda, Horiguchi, Xue, et al. 2019))
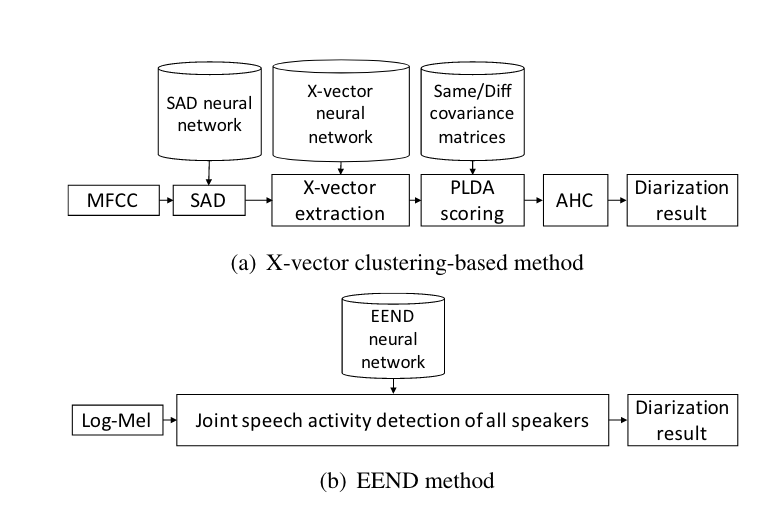
Figure 1: <&fujita2019end1>
The latter, end-to-end approach (EEND), offers lower Diarization Error Rate (DER) than former clustering ((Fujita, Kanda, Horiguchi, Xue, et al. 2019)), achiving 10.76 vs. 11.53 DER on the CALLHOME dataset respectively. However, it confers a few disadvantages: the end-to-end system produces a diarization result directly dependent on the time dimension of the input Log-Mel (i.e. it outputs probability per speaker per time slice), so its error could include both the error in voice activity detection and diarization; furthermore, the one-shot nature of this method allows no interpretation or manipulation of its actual outputs—such as specifying the number of speakers after diarization is completed (as is possible with clustering because one could simply choose the number of centroids to calculate) (Park et al. 2021).
We therefore desire here to combine the advantages of both methods discussed here in producing a diarization technique that both retains the flexible nature of vector-based approaches but also seeks to generate as complete and performant (in terms of DER) a pipeline as possible with deep learning.
Motivations
The discussion here is motivated by a few facts:
- Excellent ((Radford et al. 2022)) ASR models exist without being pre-trained on the diarization task, meaning they produce well-timed transcriptions without the speakers labels
- Well performing forced-alignment tools exist (McAuliffe et al. 2017), which can be applied on-top-of rough voice activity segments from assumption
#1(for instance, by reading attention activations; or by concatenating rough word timings). - The number of speakers is not exogenously known, yet could be specified after diarization completes.
Proposal
One of the latest advances for EEND-class models leverages the reasonably novel Convolutional Transformer (“Conformer”) architecture ((Gulati et al. 2020)) to improve the performance of the model. Specifically, the model swaps the time-delayed fully connected blocks in favor of Conformer blocks, and mixes in the SpecAugment data augmentation technique for the Log-Mel frequency input ((Liu et al. 2021)). We will use this new model both as the basis of our work, as well as the benchmark to improve upon for diarization results.
Text-Aware (Near) End-to-End Approach
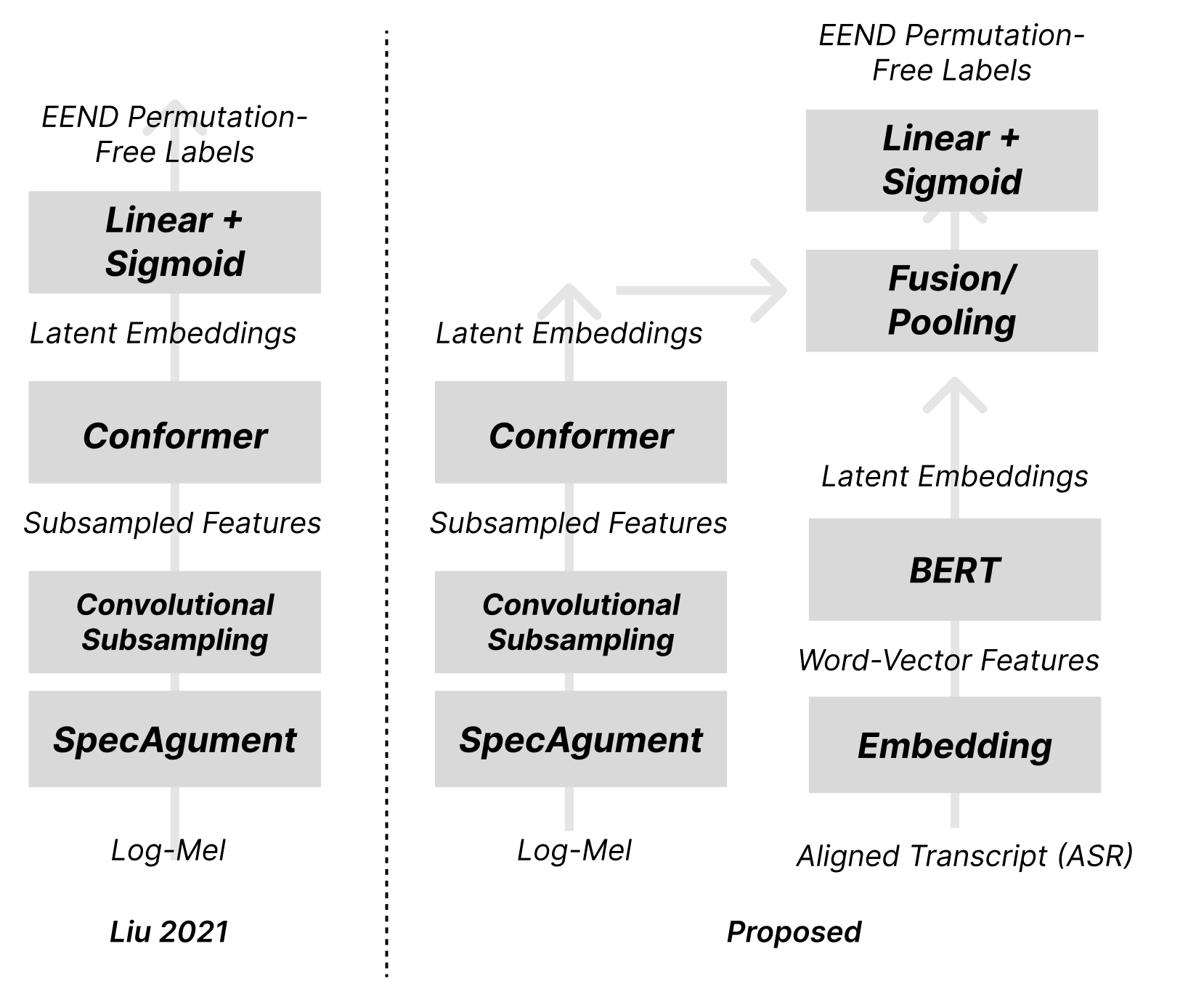
Contextual and positional information (for instance, raving pronoun use) provides a useful basis by which humans recognize the flow of an utterance used to diarize speech.
Assumption #2 above indicates that one could identify segments of text transcripts corresponding to the input audio—albeit not diarized. We hypothesize that leveraging the information from text transcripts (even if not tightly aligned) will help the model track the flow of conversation and get better diarization performance.
In the figure above, we specifically chose the Transformer BERT encoder ((Devlin et al. 2018)) to process a segment of text ASR corresponding to the input log-mel audio. The processed Bert latents are added and statistically pooled to the Conformer outputs from processing the audio signals; the fused embeddings are then passed through a fully-connected classification head for the usual labeling consistent with EEND ((Fujita, Kanda, Horiguchi, Nagamatsu, et al. 2019)).
By training a multimodal scheme in this manner, we hope to demonstrate an improved level of performance which fusing ASR text can provide to the diarization task.
Improved X-Vector via Conformers
Design constraint #3 which we outlined earlier was the desire to identify extogenously the number of speakers. While an extension below explores the possibility of this in an end-to-end architecture, conventional probabilistic clustering methods (even including neural components, such as (Snyder et al. 2018)) allow manually specified clusters to be created and tagged using PLDA ((Kenny et al. 2013)) or HMMs ((Landini et al. 2022)).
One direct extension to this approach would be the use of the Conformer architecture highlighted above in place of the fully-connected network ((Snyder et al. 2017)) which forms the basis of the x-vector approach.
To perform this, the x-vector representations would be swapped directly for the final latent from the EEND Conformer architecture prior to the fully-connected prediction head. All other post-processing of x-vectors, we hypothesize, could be applied to the new latents with minimal changes.
Specifically, convolution self-attention in the Conformer architecture work in a similar pattern to ((Peddinti, Povey, and Khudanpur 2015)) to scan across time frames; however, self-attention is a trained parameter, allowing the timescale dependence to be adaptive to the context provided.
Further adaptive training—including training on previously segmented voice activity, and/or taking MFCC instead of Log-Mel as input—maybe needed mostly following the training objectives in ((Snyder et al. 2018)) in order for the latent vectors to reflect the characteristics of new, unknown speakers.
Other Possibilities
Text and Vectors
One direct correlary of the two proposals above is simply concatenating the novelty of each: creating text+audio transformer based latent embeddings as the basis for speaker clustering.
Speaker-Count Signal
Clustering approaches, although more explainable, does confer some disadvantages. For instance, it will have no good way forward to predict overlapping speakers (as “a speaker similar to both A and B” would appear in a similar place in the latent space as “A and B are crosstalking”).
Returning to the EEND approach, however, brings into focus the question regarding speaker count. One possibility for addressing this involves injecting an extra token—either in the “text” portion of the multimodal implementation, or perhaps simply fused into the input of the original diarizing Conformer (i.e. (Liu et al. 2021))—representing the number of speakers.
Then, we will add a large negative positive term to the loss associated with incorrectly-used (i.e. out of bounds) speaker ID classes.
Unfortunately, because of the minimal weight of one speaker-count feature compared to the audio sample, and the Gaussian nature of neural networks, this method will provide no garantees regarding the actual diarization outputs.