take audio
calculate Mel Scale representation
apply a series of Filter Banks which attenuates the input to highlight groups of frequencies
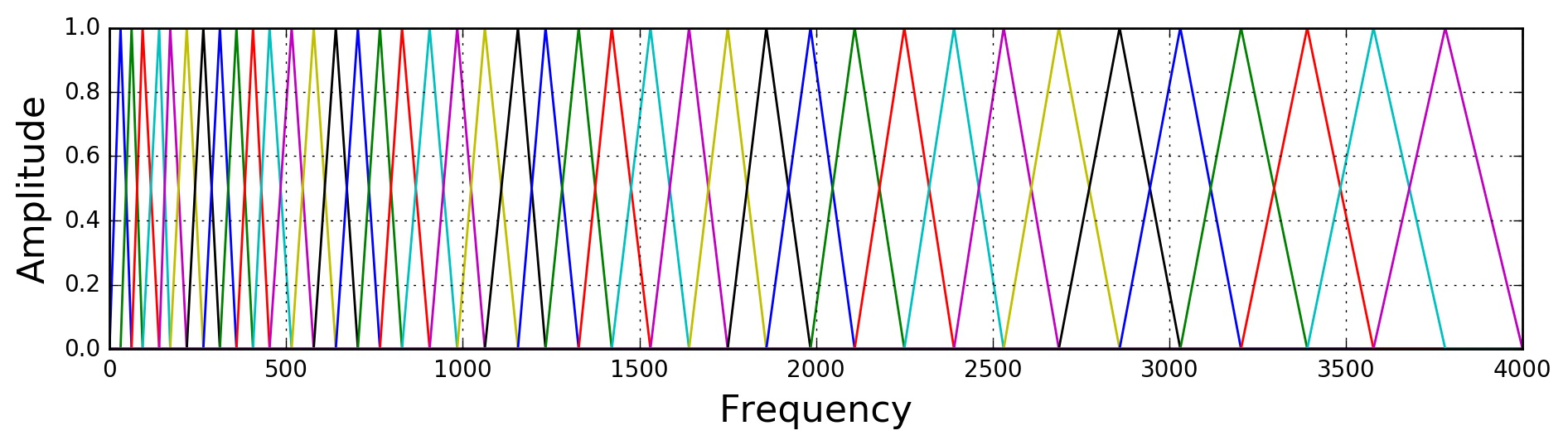
we then run a discrete-cosine transform to obtain MFCCs, because much of the output results will still correlate with each other