autism
Last edited: August 8, 2025autism is a spectrum disorder that are caused by both environmental and genetic factors.
Key Question: how can different chromatin regulators lead to the same set of symptoms named “autism”.
autism gene signature
The gene signature of autism can be measured in clean and quantitative assays.
Automatic Differentiation
Last edited: August 8, 2025Forward Accumulation
First, make a computation graph.
Consider \(\ln (ab + \max (a,2))\)
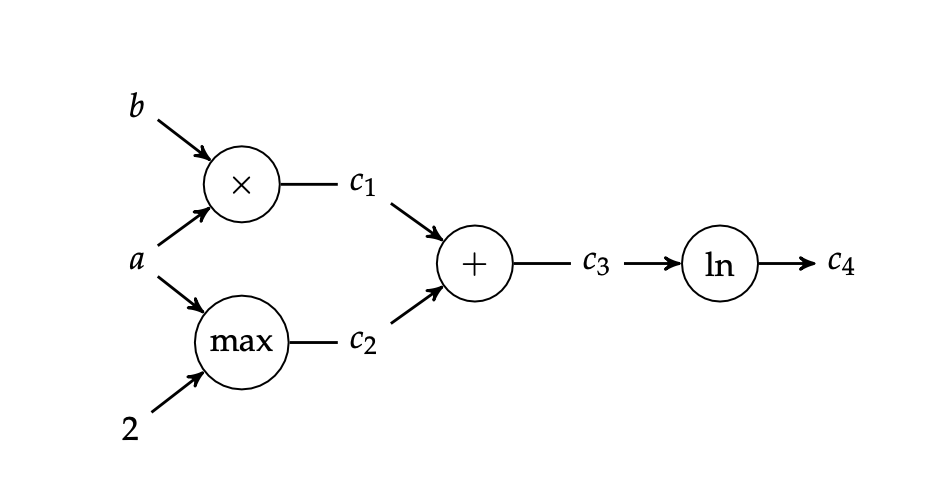
Say we want \(\pdv{f}{a}(3,2)\).
Let’s begin by tracking, left to right, both the value of each node and its derivative.
Layer 1:
- \(b = 2, \pdv{b}{a} = 0\)
- \(a = 3, \pdv{a}{a} = 1\)
Layer 2:
- \(c_1 = a\times b = 6, \pdv{c_1}{a} = b\pdv{a}{a} + a \pdv{a}{b} = 2\)
and so on; until we get to \(c_4\)
autonomous ODEs
Last edited: August 8, 2025an First Order ODE is “autonomous” when:
\begin{equation} y’ = f(y) \end{equation}
for some \(f\) of one variables. Meaning, it only depends on the independent variable \(t\) through the use of \(y(t)\) in context.
This is a special class of seperable diffequ.
autonomous ODEs level off at stationary curves
for autonomous ODEs can never level off at non-stationary points. Otherwise, that would be a stationary point.
See stability (ODEs)
time-invariant expressions
For forms by which:
axiomatic semantics
Last edited: August 8, 2025Pre-conditions and post-conditions for specify logical formula; this is the basis of verification systems.
Axler 1.A
Last edited: August 8, 2025Key sequence
- In this chapter, we defined complex numbers, their definition, their closeness under addition and multiplication, and their properties
- These properties make them a field: namely, they have, associativity, commutativity, identities, inverses, and distribution.
- notably, they are different from a group by having 1) two operations 2) additionally, commutativity and distributivity. We then defined \(\mathbb{F}^n\), defined addition, additive inverse, and zero.
- These combined (with some algebra) shows that \(\mathbb{F}^n\) under addition is a commutative group.
- Lastly, we show that there is this magical thing called scalar multiplication in \(\mathbb{F}^n\) and that its associative, distributive, and has an identity. Technically scalar multiplication in \(\mathbb{F}^n\) commutes too but extremely wonkily so we don’t really think about it.
New Definitions
- complex number
- field: \(\mathbb{F}\) is \(\mathbb{R}\) or \(\mathbb{C}\)
- list
- \(\mathbb{F}^n\): F^n
Results and Their Proofs
- properties of complex arithmetic
- commutativity
- associativity
- identities
- additive inverse
- multiplicative inverse
- distributive property
- properties of \(\mathbb{F}^n\)
- addition in \(\mathbb{F}^n\) is associative
- addition in \(\mathbb{F}^n\) is commutative
- addition in \(\mathbb{F}^n\) has an identity (zero)
- addition in \(\mathbb{F}^n\) has an inverse
- scalar multiplication in \(\mathbb{F}^n\) is associative
- scalar multiplication in \(\mathbb{F}^n\) has an identity (one)
- scalar multiplication in \(\mathbb{F}^n\) is distributive
Question for Jana
- No demonstration in exercises or book that scalar multiplication is commutative, why?
Interesting Factoids
- You can take a field, look at an operation, and take that (minus the other op’s identity), and call it a group
- (groups (vector spaces (fields )))