Democracy Index
Last edited: August 8, 2025DeMorgan's Law
Last edited: August 8, 2025Suppose you have two non mutually exclusive sets \(E\) or \(F\).
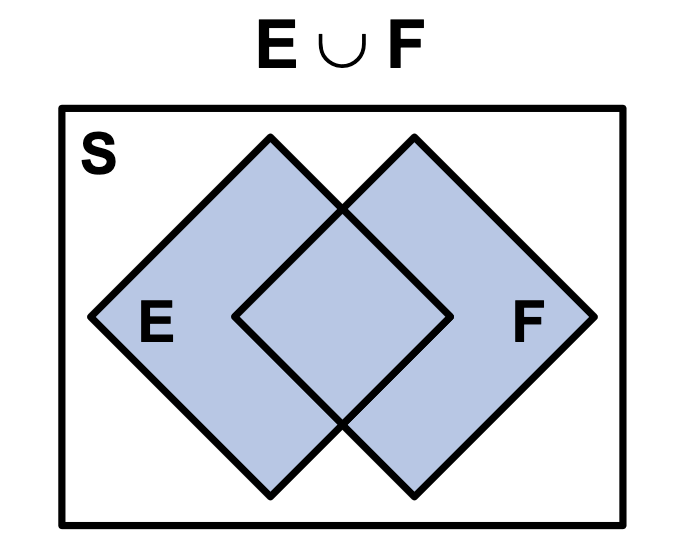
\begin{equation} (E\ and\ F)^{C} = (E^{C}\ or\ F^{C}) \end{equation}
\begin{equation} (E\ or\ F)^{C} = (E^{C}\ and\ F^{C}) \end{equation}
depression
Last edited: August 8, 2025derivational words
Last edited: August 8, 2025Derivat
derivative (finance)
Last edited: August 8, 2025a