Dropout Project Board
Last edited: August 8, 2025
https://aclanthology.org/2024.naacl-long.301.pdf
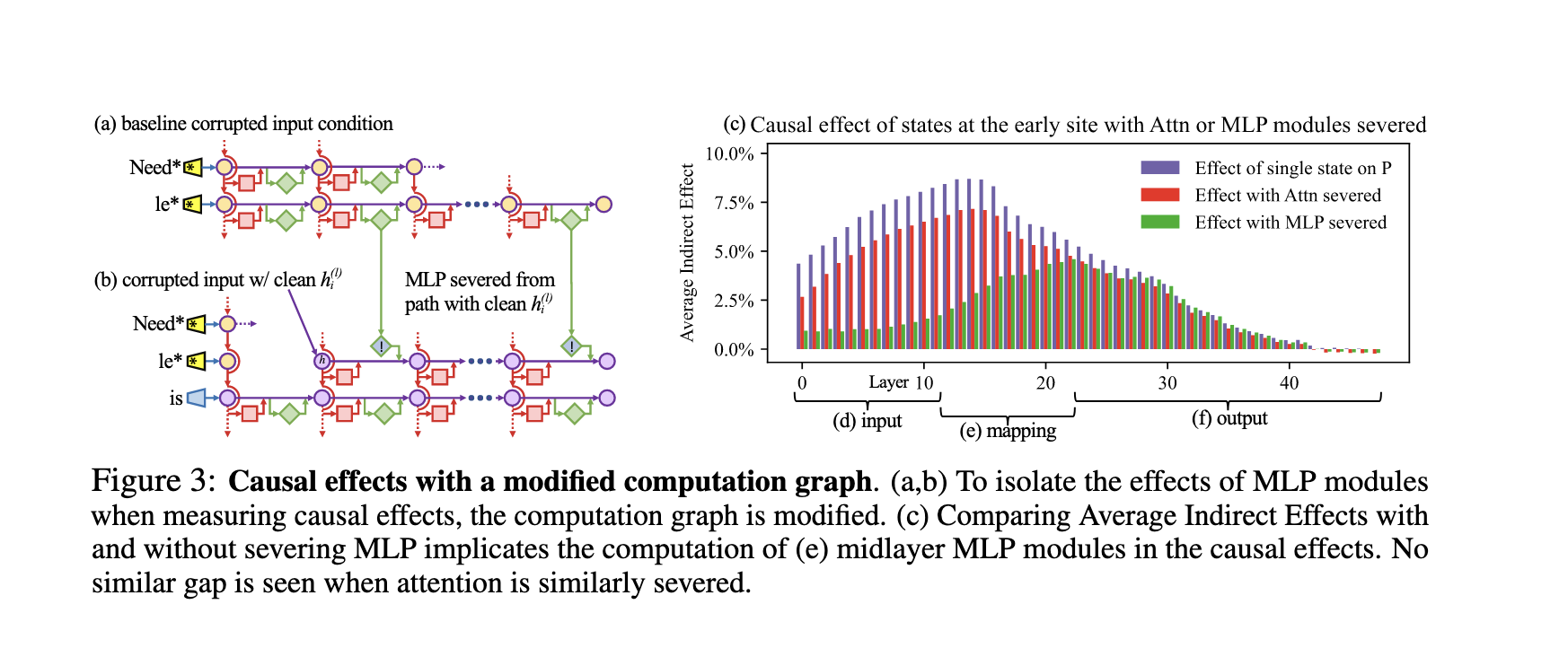
Pararel
Drug Resistance
Last edited: August 8, 2025Drug Resistance is the process of developing resistance to drugs after some time of use
occurrence of Drug Resistance
Drug Resistance occurs when there’s a mutation that causes macromolecular changes which causes virus to no longer bind the drug but still maintain the same function
dual space
Last edited: August 8, 2025The dual space of \(V\), named \(V’\), is the vector space formed by linear functionals on \(V\) (because recall set of linear maps between two vector spaces form a vector space).
constituents
A vector space \(V\)
requirements
\(V’ = \mathcal{L}(V, \mathbb{F})\) , and its a vector space.
additional information
dimension of dual space is equivalent to the original space
\begin{equation} \dim V’ = \dim V \end{equation}
Proof:
Because \(\dim \mathcal{L}(V,W) = (\dim V)(\dim W)\), and \(V’ = \mathcal{L}(V, \mathbb{F})\). Now, \(\dim V’ = \dim \mathcal{L}(V,\mathbb{F}) = (\dim V)(\dim \mathbb{F}) = \dim V \cdot 1 = \dim V\).
Dup15q Syndrome
Last edited: August 8, 2025Dup15q Syndrome is an autistic syndrome associated with a gain of variant function in UBE3A. It is the opposite of Angelman Syndrome, which is a loss of function result on UBE3A.
Dynamic RC Circuits
Last edited: August 8, 2025Capacitor charging:
\begin{equation} Q = Q_0 (1-e^{-\frac{t}{RC}}) \end{equation}
where \(Q\) is capacitor change at time \(t\), and \(Q_0\) initial change, and \(RC\) the resistance and capacitance.
Where, \(RC\) is called the “time constant”.
\begin{equation} I = \frac{V}{R} (e^{-\frac{t}{RC}}) \end{equation}
Note! these are inverse relationships: as a capacitor CHARGE, the current DROPS.