Finite State Machine
Last edited: August 8, 2025A graph of states which is closed and connected.
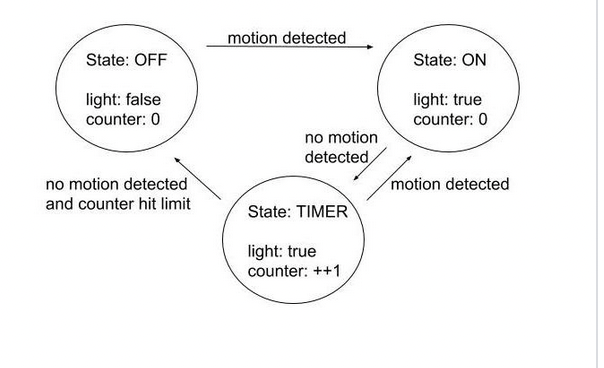
Also relating to this is a derived variable. One way to prove reaching any state is via Floyd’s Invariant Method.
finite-dimensional vector space
Last edited: August 8, 2025A finite-dimensional vector space is a vector space where some actual list (which remember, has finite length) of vectors spans the space.
An infinite-demensional vector space is a vector space that’s not a finite-dimensional vector space.
additional information
every finite-dimensional vector space has a basis
Begin with a spanning list in the finite-dimensional vector space you are working with. Apply the fact that all spanning lists contains a basis of which you are spanning. Therefore, some elements of that list form a basis of the finite-dimensional vector space you are working with. \(\blacksquare\)
Fireside Chats
Last edited: August 8, 2025Fireside Chats are a group of broadcasts by Franklin D. Roosevelt (FDR) which allowed him to speak directly to the people.
Fireside Index
Last edited: August 8, 2025Below you will find a list of the Fireside articles.
| Article | Date |
|---|---|
| Welcome to the Fireside | |
| Make Models Go Brrr | |
| Todo Lists | |
| “Let’s find time” | |
| Pipes are so bad |
First Order ODEs
Last edited: August 8, 2025First Order ODEs are Differential Equations that only takes one derivative.
Typically, by the nature of how they are modeled, we usually state it in a equation between three things:
\begin{equation} t, y(t), y’(t) \end{equation}
as in—we only take one derivative.
Sometimes the solution may not be analytic, but is well-defined:
\begin{equation} y’ = e^{-x^{2}} \end{equation}
we know that, by the fundamental theorem of calculus, gives us:
\begin{equation} y(x) = \int_{0}^{x} e^{-s{2}} \dd{s} \end{equation}