SU-EALC110 JAN202025
Last edited: January 1, 2026Legends in Classical Chinese
Story of Ch’un-hyang is in essence a story of marvel; i.e. a 传奇—a “legend”. Confucian scholar-officials shun this type of work as a function of it talking about fantastical scenes.
In some sense similar to the online novel scene now: reasonably interesting but not analyzed in serious scholarship.
Joseon period social liberality was largely destroyed by Japanese colonial invasion.
Consider
- who is the narrator?
- when does the narrator sing a song
- what are the function of excessive details?
- where are the puns and why?
convex problem
Last edited: January 1, 2026Recall optimization (math). An optimization (math) problem is convex if:
- the objective is convex function
- inequality constrains’ functions are convex
- equality constrains are affine
Special convex problems
Optimality Criterion for Differentiable Objective
\(x\) is optimal IFF its feasible and
\begin{equation} \nabla f_{0} \qty(x)^{T} \qty(y-x) \geq 0 \end{equation}
for all feasible \(y\).
examples
- unconstrained problem: \(x\) minimizes \(f_{0}\qty(x)\) IFF \(\nabla f_{0}\qty(x) = 0\)
- equality constrained problem: \(x\) minimizes \(f_{0}\qty(x)\) subject to \(Ax = b\) IFF there is a \(v\) such that \(Ax = b\), \(\nabla f_{0}\qty(x) + A^{T}v = 0\)
Local and Global Optima
Any locally optimal point of a convex problem is globally optimal.
Convex Problem Hiearchy
Last edited: January 1, 2026A Linear Program is equivalent to an SDP
cornucopia of analysis
Last edited: January 1, 2026Pythagorean Theorem
\begin{equation} \|u + v\|^{2} = \|u \|^{2} + \|v\|^{2} \end{equation}
if \(v\) and \(u\) are orthogonal vectors.
Proof:
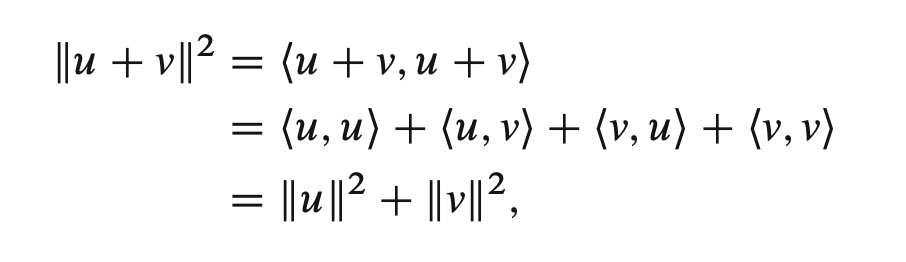
An Useful Orthogonal Decomposition
Suppose we have a vector \(u\), and another \(v\), both belonging to \(V\). We can decompose \(u\) as a sum of two vectors given a choice of \(v\): one a scalar multiple of \(v\), and another orthogonal to \(v\).
That is: we can write \(u = cv + w\), where \(c \in \mathbb{F}\) and \(w \in V\), such that \(\langle w,v \rangle = 0\).
Linear Constraint Optimization
Last edited: January 1, 2026\begin{align} \min_{x}\ &c^{\top} x + d \\ s.t.\ &Gx \preceq h \\ & Ax = b \end{align}
- linear objective function
- linear constraints
single our inequality forms a half-space; the entire feasible set is denoted by a series of linear functions—-these linear equalities are each CONVEX. The resulting feasible set, then, is ALSO convex—-meaning any line within the set remains within the set. So, any local minimum is a global minimum.
This is a convex problem where all constrains and objectives are affine.