MedBlindTuner
Last edited: August 8, 2025One possible approach for using homomorphic encryption, developed specifically for imaging data.
- extract relevant features locally
- resulting data is encrypted using FHE
- train model remotely using FHE encrypted data
- send model back, and data owners decrypt the inference results locally
Medical Dialogue Generation
Last edited: August 8, 2025RAG for generic risk conversations.
- tag transcripts with the relevant themes a la action research
- use llama2 to embed the given information
- then send the overall information to a larger language model
People generally preferred grounded GPT responses over human responses. Sometimes, in 2 of the features, humans preferred the non grounded responses.
Medical Knowledge Extraction
Last edited: August 8, 2025SnowMed CT: large medical ontology
- created pairwise distance matrix on SnowMed CT
- created weighted graphs using the SnowMed information
- Node2Vec! Suddenly you have an embedding for each disease.
Two Tasks:
Patient Disease Embeddings
Using the node2vec with snowmed
Similar Patient Retrial
Reveal hidden co-morbidities via Jaccard Coefficient
meeting 7/25
Last edited: August 8, 2025meeting 8/1
Last edited: August 8, 2025Updates
- dropping dropout: https://proceedings.mlr.press/v202/geiping23a/geiping23a.pdf
- CAW-coref: revised! do we need more space for things such as a figure?
- stanza 1.9.0 staged! https://huggingface.co/stanfordnlp/stanza-en
Yay mend works!
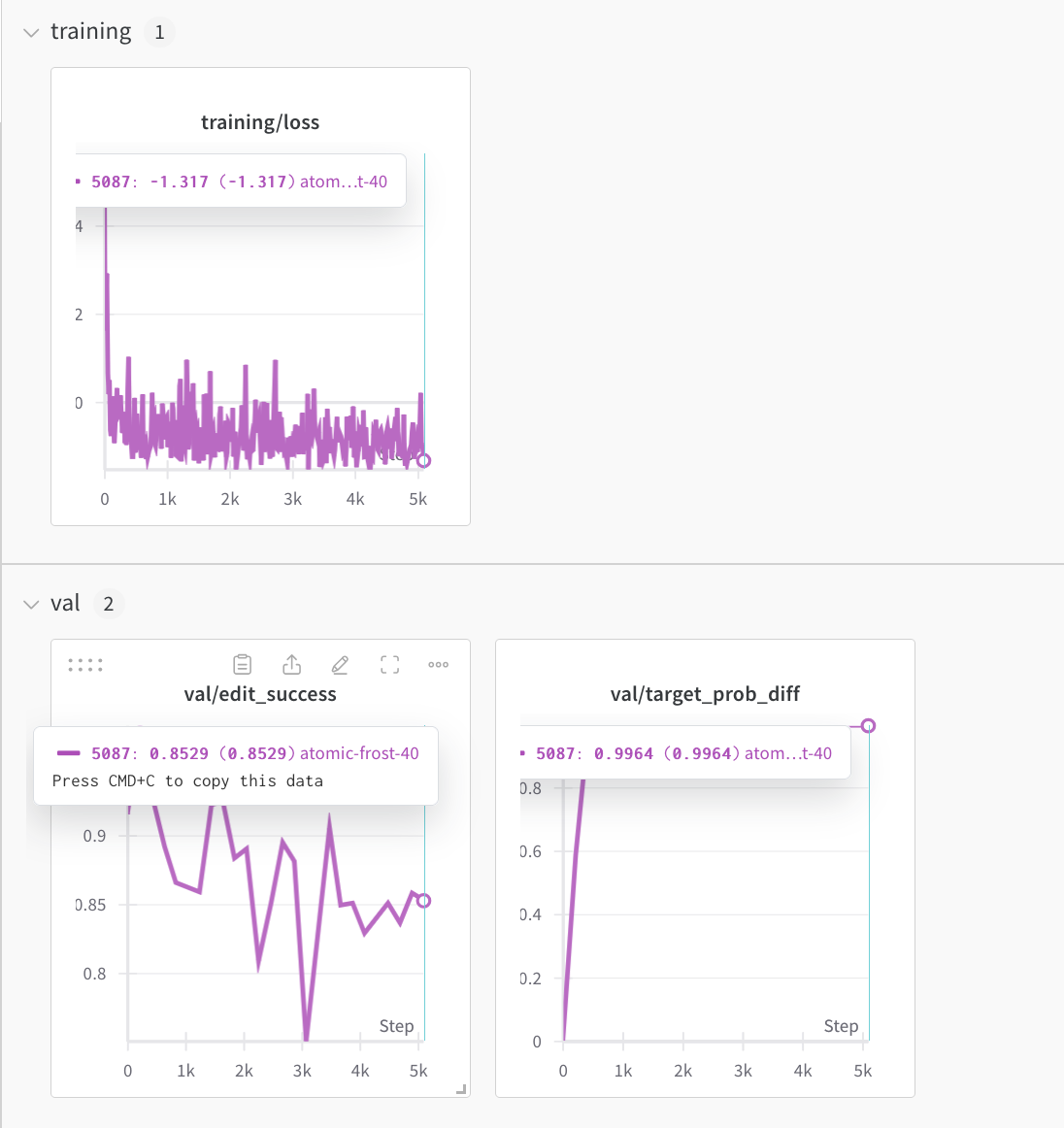
.mean() vs. .sum() for the dW maps?
PPL Isn’t the Only Possible Metric
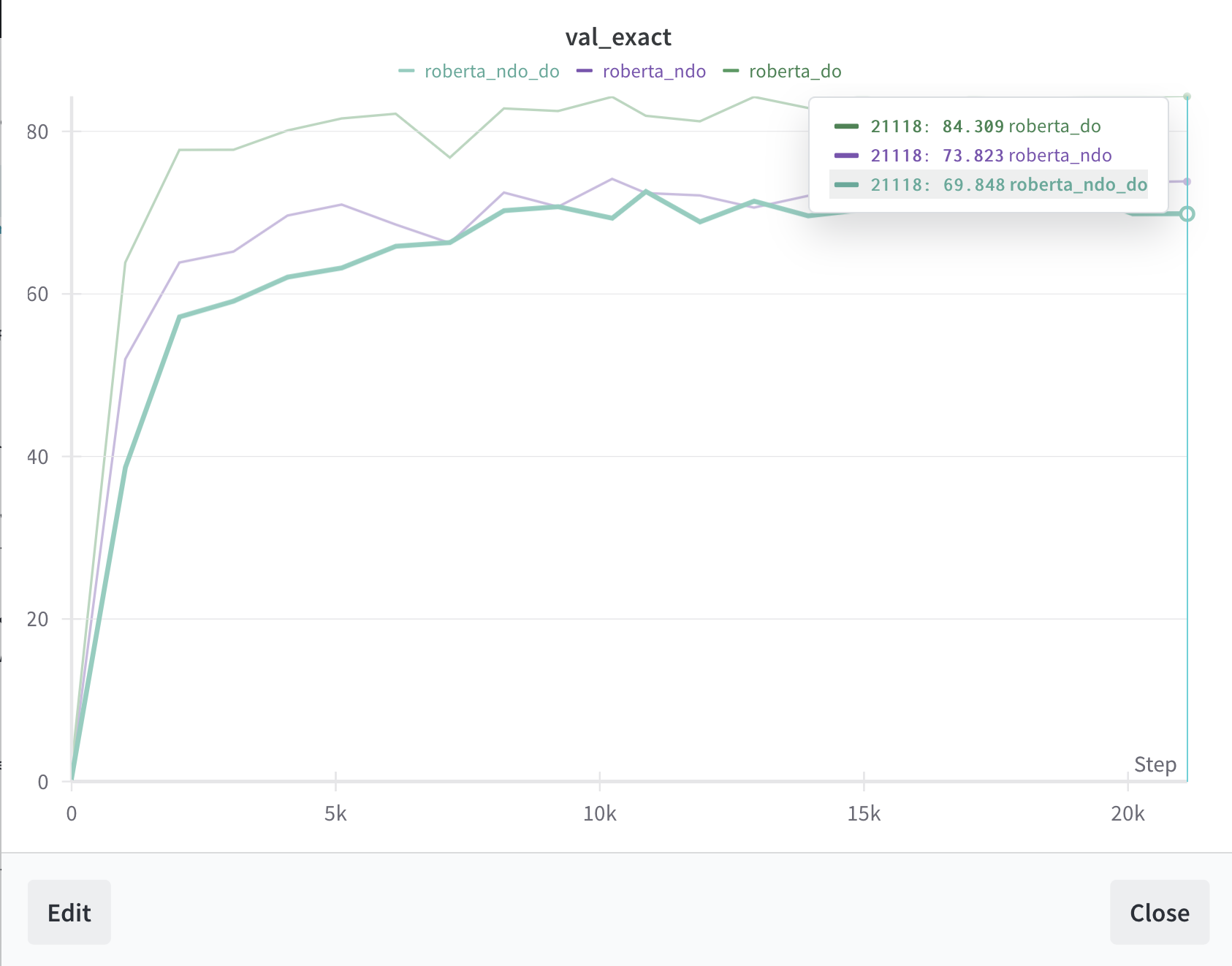
even if our model is better ppl, its worse at squad than Facebook (granted its been trained a lot less); will run with new pretraining model (expect that no dropout will be better (see paper above)).