Meghanani 2021
Last edited: August 8, 2025DOI: 10.3389/fcomp.2021.624558
One-Liner
analyzed spontaneous speech transcripts (only!) from TD and AD patients with fastText and CNN; best was \(83.33\%\) acc.
Novelty
- threw the NLP kitchen sink to transcripts
- fastText
- CNN (with vary n-gram kernel 2,3,4,5 sizes)
Notable Methods
- embeddings seaded by GloVe
- fastText are much faster, but CNN won out
Key Figs
the qual results
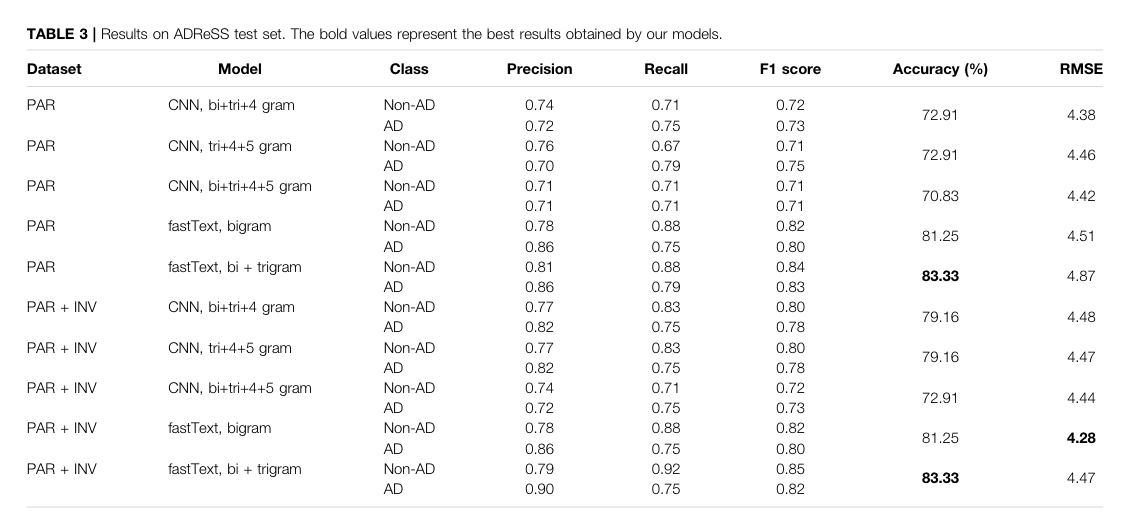
PAR (participant), INV (investigator)
Notes
Hey look a review of the field:
Mel Scale
Last edited: August 8, 2025Human do not perceive frequency very well. The Mel scale is a scale from Hertz to what’s better perceived.
memory
Last edited: August 8, 2025memory allocation
Last edited: August 8, 2025Utilization vs throughput is conflicting goals.
Big Picture
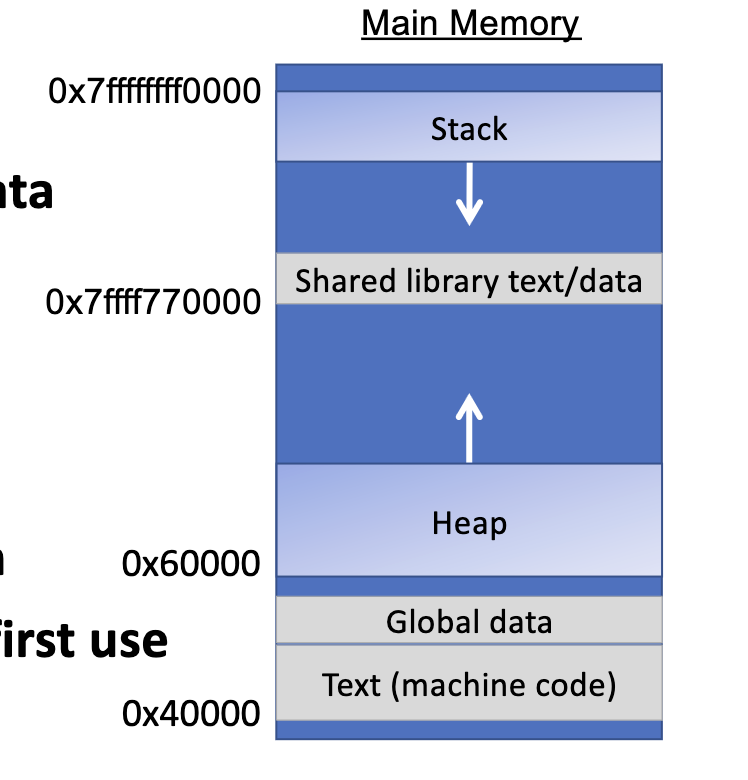
OS:
- creates new process
- sets up address space/segments
- read the executable, load instructions, global data
- libraries gets loaded
Complier:
- set up stack
Heap Allocator: “Sandbox of bytes”
- initialize the heap
heap allocation: client
void *malloc(size_t size);
Returns a pointer to a block of heap memory of at least size bytes, or NULL if an error occurred.
void free(void *ptr);
Frees the heap-allocated block starting at the specific address.
Mencius Philosophy
Last edited: August 8, 2025Mencius Philosophy: every person has the capability of goodness and harm, and whichever one you water is the one that grows.