SU-EE364a JAN062026
Last edited: January 1, 2026Key Sequence
Notation
New Concepts
Important Results / Claims
Questions
Interesting Factoids
SU-SOC175 JAN072025
Last edited: January 1, 2026::PROPERTIES: :ID: 5440B722-5661-4B1A-99D2-B6D48481DDA2 :END:
Potential measures of China’s decline:
- purchasing power is not as high even if its a huge economy
- incomes are not rising as fast as they did before
- model of property-driven growth
influences
- China’s working age productivity is shrinking
- China’s total productivity has decreased
- ROI from Chinese companies have declined
- …and thus foreign direct investment is reversing
bailouts
Unlike the US financial crisis, when big companies go bust, China didn’t bail out companies except to finish already-purchased homes.
SU-STS115 JAN072025
Last edited: January 1, 2026four pillars of medical ethics
- beneficence: act in the best interest of the patience
- non-maleficence: do no harm
- autonomy: respect the right of people to make decisions for themselves
- justice: seek fairness with what we do
…on children
- autonomy is very adult centric… “substituted judgment is hard”
- altruistic surrogacy: act in the children’ best interest
- altruism: doesn’t require the consent / knowledge of others + doing something for someone else
ethical equivalency
Agreeing to withhold a treatment is equivalent to agreeing to stop it.
supporting hyperplane theorem
Last edited: January 1, 2026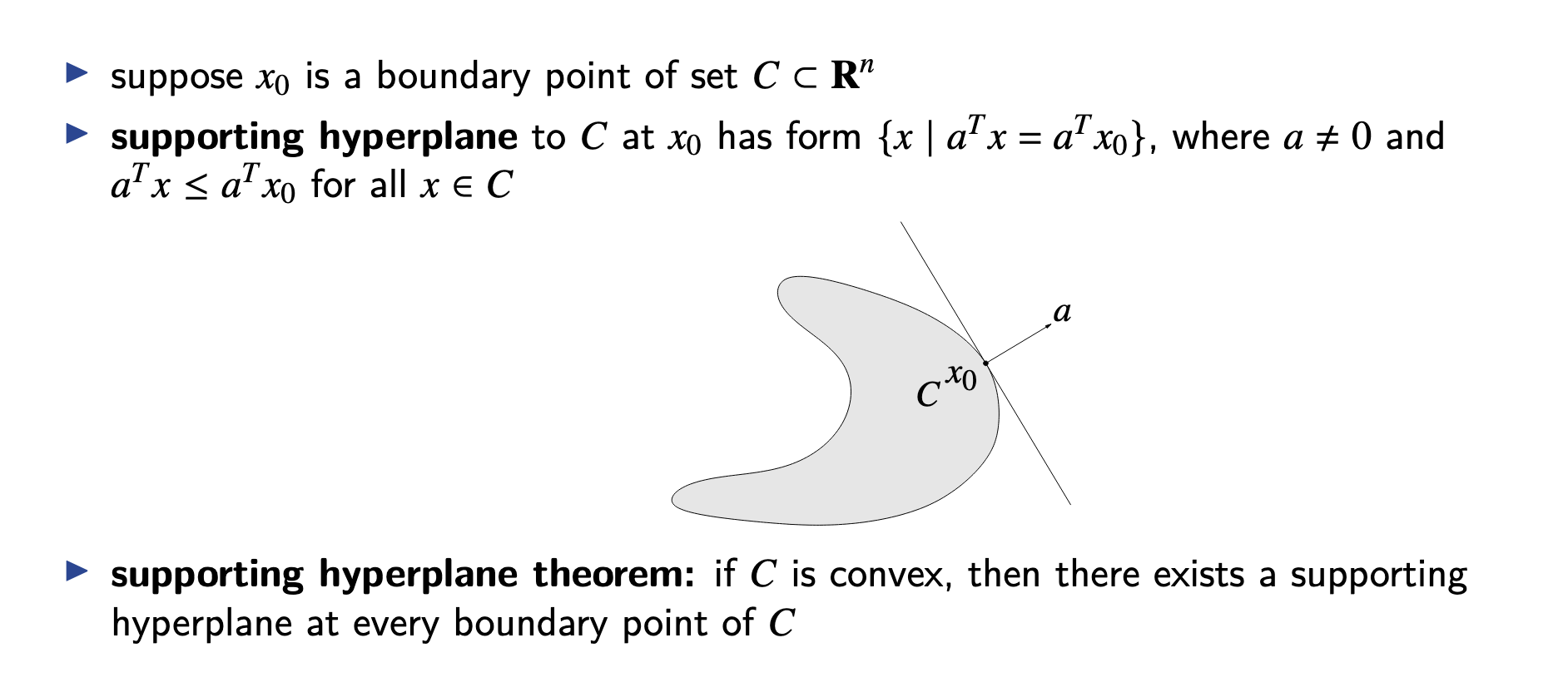
AI Incidents Policy
Last edited: January 1, 2026Talk by Lisa Soder
AI Regulation
- EU GPAI Code of Practice: makes fronter model providers track, document, and report AI incidents
- SB 53 Large Developer: identify and respond to safety incidents + internal governance
Problem: define what it means to “track, document, and report”?
Methods
Goals
- help companies with compliance
- help regulators for assessing compliance
- technical tooling
Approach
- legal analysis
- best practices in AI
- best practices in other domains
What is an AI incident?
“In house evaluation is not enough.”