EMNLP2025 Index
Last edited: December 12, 2025Talks
- EMNLP2025 Keynote: Heng Ji
- EMNLP2025 Eo: Expert Generalization in MOE
- EMNLP2025 Wu: Zero Shot Graph Learning
- EMNLP2025: MUSE, MCTS Driven Red Teaming
Posters
Takes
- although parsing maybe dead for natural language, structure helps parse scientific information (i.e. drugs, molecules, proteins, etc.)
- two idea: 1) how to formalize approach mathematically 2) what can LMs do that humans can’t do?
- information-rich statefulness + constraints for pruning space is the unlock for ability to build on previous results; i.e. “critical thinking”
Tasks to Do
- EMNLP2025 Fan: medium is not the message: I wonder if we can remove keyboard based signals from BM25 using this method
- EMNLP2025 Xu: tree of prompting: a bunch of multi-hop retrieval datasets to benchmark for RAG-DOLL
- EMNLP2025 Bai: understanding and leveraging expert specialization of context faithfulness: a good set of retrieval benchmarks
Tasks Can Do
- EMNLP2025 Keynote: Heng Ji: “protein LLM requires early exit to capture dynamical Beauvoir”; what if we Mixture of Depth a protein LM?
- EMNLP2025 Hutson: measuring informative of open and questions: formalize this as a rho– POMDP , or use actual value of information measures with Belman backup
- EMNLP2025 Karamanolakis: interactive machine teaching: use MCTS UCB to pick the next set of constitutions to optimize for
- EMNLP2025 Yu: Long-Context LM Fail in Basic Retrieval: I wonder how thoughtbubbles do on the dataset
- EMNLP2025 Bai: understanding and leveraging expert specialization of context faithfulness: could be interesting using the same freeze/clamping technique for cultural work
- EMNLP2025 Vasu: literature grounded hypothesis generation: maybe could use its same hypothesis generation pipeline for RAG
- EMNLP2025Li: enhancing RAG RESPONSE evaluator: maybe could be useful to use to evaluate edge rewards for RAGDOLL
mixed-autonomy traffic
Last edited: December 12, 2025Vehicle Platooning
advantages:
- reduce conjection
- greater fuel economy
hierarchical control of platoons
- vehicle: lat and long
- link: formulation, splitting, reordering
- network: planning, goods assignment, etc.
Goal: can we dynamically form platoons that minimizes travel time while minimizing fuel cost?
Traffic Coordination with MARL
To coordinate UAVs, we can formulate it as a Decentralized POMDP Problem. Key insight: rollout both you and a simulation of others.
Also run MPC with trurcated rollouts
MoE Review Index
Last edited: December 12, 2025Project Thoughts
Overall Question: “Why is growing a better idea than training larger models from scratch?”
Cost of Specialization
Sub-Question: “how much does load balancing loss incur in terms of performance versus specialized data?”
- For our goals, our data is much more specific (i.e. personalized), meaning we don’t necessarily need to rely on the ModuleFormer load balancing loss tricks.
- Switch Transformers tells us that standard regularization, including dropout, means that one expert can be sufficient to answer many questions (perhaps 1+1 like in shared expert setups)
How Much Expert is an Expert?
Sub-Question: “do all experts have to have the same representational power?”
MOEReview Fedus: Switch Transformers
Last edited: December 12, 2025At scale, with regularization (including dropout), k=1 on expert routing is fine!
MOEReview Gale: MegaBlocks
Last edited: December 12, 2025Standard MoEs either waste computation by padding unused capacity within each expert, or drop tokens assigned to an expert when it exceeds capacity (i.e. truncate so that we don’t have to pad too much).
Method
Instead of
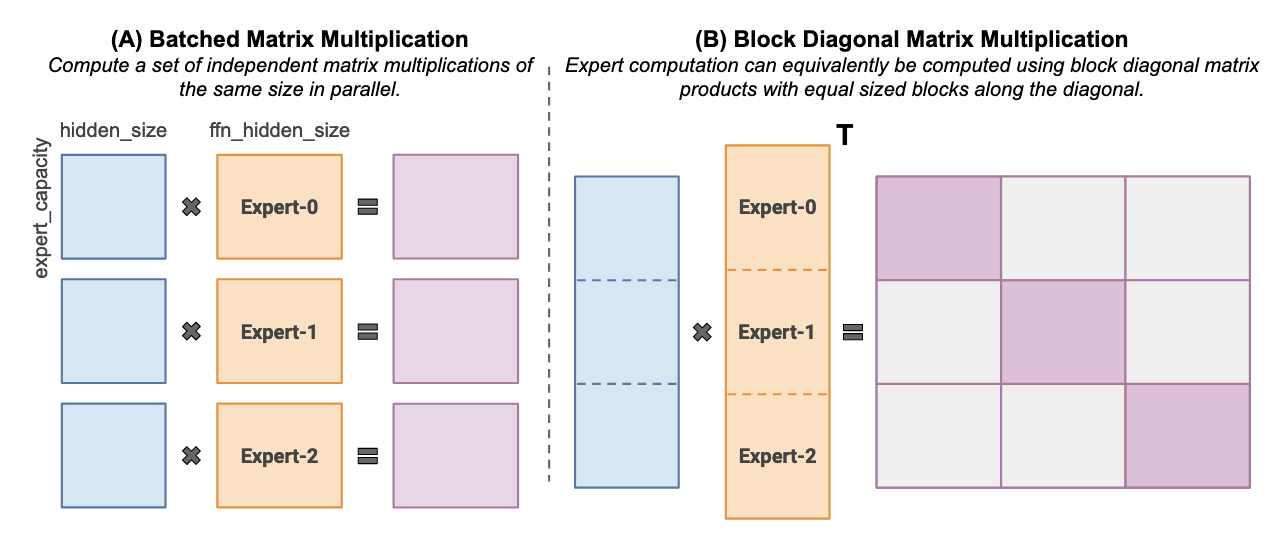
we do
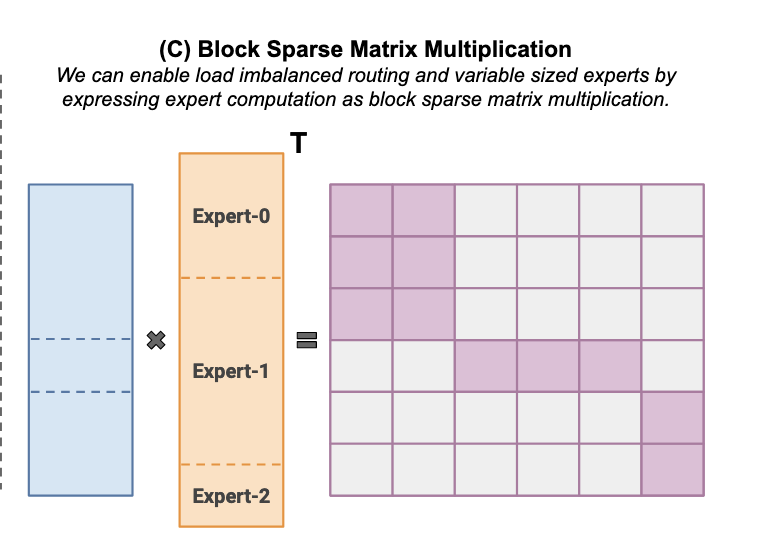
and leverage efficient block sparse multiplication to have variably-sized experts.