PGA
Last edited: August 8, 2025PGA extends controller gradient ascent to cover CPOMDPs
Notation
Recall from controller gradient ascent we have an objective which we will modify for CPOMDPs. For initial controller-states \(\beta\) and utility \(\bold{u}_{\theta}\):
\begin{equation} \max_{\theta}\ \beta^{\top} (\bold{I} - \gamma \bold{T}_{\theta})^{-1} \bold{r}_{\theta} \end{equation}
subject to:
- \(\Psi\) remains a probably distribution over \(|A|\)
- \(\eta\) remains a probably distribution over \(|X|\)
- and, new for CPOMDP, \(\beta^{\top} (\bold{I} - \gamma \bold{T}_{\theta})^{-1} C_{i} \leq \epsilon_{i}\ \forall i\), that is, each constraint \(C_{i} \in \bold{C}_{i}\) is satisfied to be lower than the budget \(\epsilon_{i}\).
where
phase line
Last edited: August 8, 2025\begin{equation} y’ = f(y) \end{equation}
for autonomous ODEs, we can plot a phase line
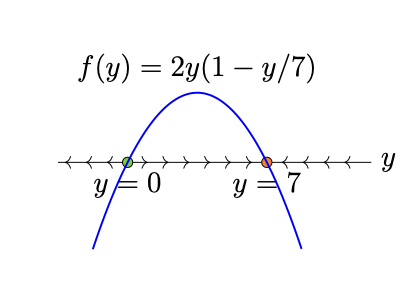
because autonomouse ODEs, we can plot such a line whereby we can analyze the direction of a solution function’s travel
a particle’s one-way motion must converge to a stationary value, or \(\pm \infty\), as \(t\) increases
physical qubits
Last edited: August 8, 2025We will leverage atoms as qubits. So, how do we isolate a qubit from an atom? We will leverage electrons.
We will select the lowest energy state as the base state; as there maybe multiple ground states, we will choose \(|u\big>\) and \(|d\big>\) from two of the states.
physics
Last edited: August 8, 2025physics is the act of explaining what we see in terms of solving for the “unseen”. For an explanation to be good, it needs to be testable.
How exactly does physics work?
“classical results”
- Newton’s laws
- Maxwell’s equations
- General relativity
“quantum theory”
A new model that actually allows particle inference.
Pineau 2006
Last edited: August 8, 2025(Pineau, Gordon, and Thrun 2006)
One-Liner
“If we can avoid the curse of history, the curse of dimensionality wouldn’t be a problem”.
Basically - most POMDP problems don’t reach much of the belief simplex. So, can we concetrate planning on more probable beliefs.
Novelty
- trajectory based approach to select beliefs
- belief set is fixed through layers: each backup results in the same number of layers