Shah 2021
Last edited: August 8, 2025DOI: 10.3389/fcomp.2021.624659
One-Liner
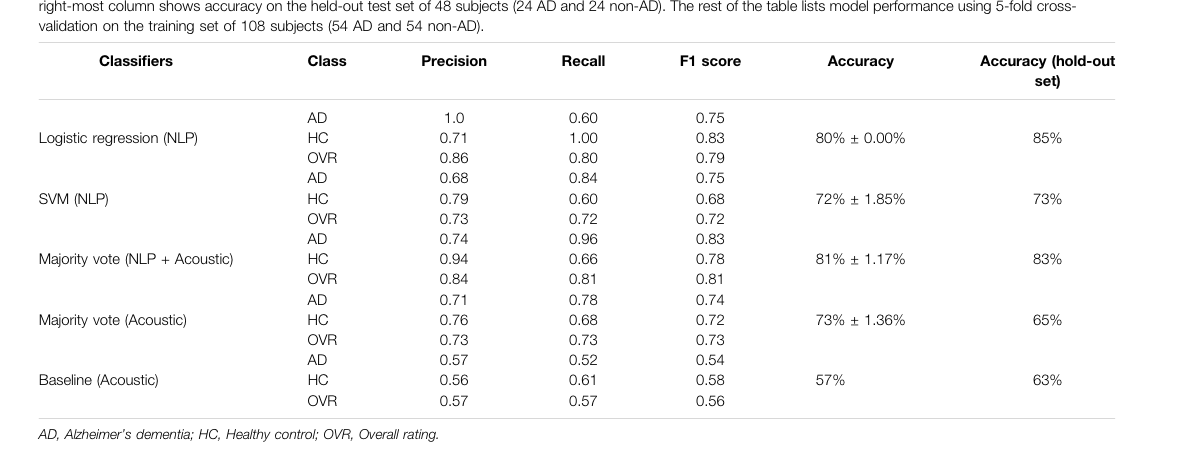
Multi-feature late fusion of NLP results (by normalizing text and n-gram processing) with OpenSMILE embedding results.
Novelty
NLP transcript normalization (see methods) and OpenSMILE; otherwise similar to Martinc 2021. Same gist but different data-prep.
Notable Methods
- N-gram processed the input features
- Used WordNet to replace words with roots
Key Figs
New Concepts
shoes and jackets
Last edited: August 8, 2025A friend recently asked for recommendations for shoes and jackets, and I realized that the links on my gear page has slowly died (very sad). So I figured I should update it with more information and alternatives.
What I (normatively) do
I’ll give specific recommendations shortly, but before I do that I feel like it’d be helpful to give some normative statements about what “good” gear to me feels like.
light, and waterproof, in that order
I try to get things that are both waterproof and light, and if both doesn’t exist (in particular for shoes), I prioritize being light.
short selling
Last edited: August 8, 2025Short selling involves betting against the stock.
Process of Short Selling
- the trader borrows a number of shares from a third party
- the trader sells them immediately for cash
- when the security dips, the debt is repaid by repurchasing the same amount of shares of the borrowed security at the lower price
- traders nets the profit from the negative price differential
If the person shorting
short squeeze
“what happened to GameStock”
sigmoid
Last edited: August 8, 2025sigmoid function is used to squash your data between \(0\) and \(1\). Sigmoid is symmetric. It could take any number and squash it to look like a probability between 0 and 1.
\begin{equation} \sigma(z) = \frac{1}{1+ e^{-z}} \end{equation}
Say you have one discrete variable \(X\), and one continuous variable \(Y\), and you desire to express \(p(x|y)\).
The simplest way to do this, of course, is to say something like:
\begin{equation} P(x^{j} \mid y) = \begin{cases} P(x^{j} \mid y) = 0, y < \theta \\ P(x^{j} \mid y) = 1, y > \theta \end{cases} \end{equation}
Signal Processing Index
Last edited: August 8, 2025Some Ideas
- Error Correction Codes
- Sampling + Quantization
- Compression Algorithms
- Frequency Domain Technologies
Two Main Goals
- Unit 1: Efficient Representation of Signal (i.e. compression)—we ideally want the smallest sequence of bits to encode the raw signal
- Unit 2: Preserving Information of Signal (i.e. communication)—we ideally want to communicate our bits while not sacrificing information despite all communication channels being noisy
Unit 1 outline
- compress the same exactly information into less space (lossless compression)
- what is information (probability and entropy)
- compression and limits of compression (Huffman Coding)
- removing irrelevant/uninteresting information (lossy compression)
- key idea: “frequency domain can be aggressively compressed”
- signals, frequency representation, bandwidth (discrete cosine transform)
- quantization, sampling, reconstruction (encoding analog signal into digital signal)
Unit 2 outline
- communication basics (channels and noise)
- representing bits for physical/analogue communication (modulation—encoding digital signal into analog signal)
- bandwidth, spectrum shaping/sharing (frequency-domain filtering)
- fundamental limits (channel capacity)
- separation of compression and communication (separation principle)
- adding redundancy to communication schemes (error-correcting codes)