SU-CS161 Midterm Sheet
Last edited: October 10, 2025SU-CS161 OCT092025
Last edited: October 10, 2025Motivating Questions
Can we do better than \(O\qty(n \log n)\) sort?
- What’s our model of computation?
- What are some reasonable models of computation?
comparison based sorting
merge sort, quicksort, insertion sort.
- you can’t access values directly
- you can only compare two items (i.e. if something is better / smaller than another)
Any deterministic, comparison-based sorting algorithm must take \(\Omega\qty(n \log\qty(n))\) steps of computation.
Proof idea—any comparison based sorting algorithm gives rise to a decision tree. The decision tree must have this many steps. The structure of the tree is as follows: nodes are each comparison decision, each nodes has 2 children (one for each ordering between two items), leaf nodes represents the output. The deepest leaf gives the lower bound.
Bayesian Network Naive Bayes
Last edited: October 10, 2025Naive Bayes is a special class of Baysian Network inference problem which follows a specific structure used to solve classification problems.
The Naive Bayes classifier is a Baysian Network of the shape:
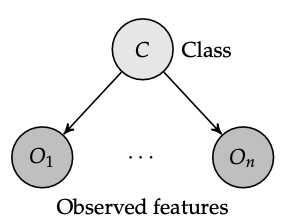
(Why is this backwards(ish)? Though we typically think about models as a function M(obs) = cls, the real world is almost kind of opposite; it kinda works like World(thing happening) = things we observe. Therefore, the observations are a RESULT of the class happening.)
Gaussian distribution
Last edited: October 10, 2025constituents
- \(\mu\) the mean
- \(\sigma\) the variance
requirements
\begin{equation} X \sim N(\mu, \sigma^{2}) \end{equation}
Its PDF is:
\begin{equation} \mathcal{N}(x \mid \mu, \sigma^{2}) = \frac{1}{\sigma\sqrt{2\pi}} e^{ \frac{-(x-u)^{2}}{2 \sigma^{2}}} \end{equation}
where, \(\phi\) is the standard normal density function
Its CDF:
\begin{equation} F(x) = \Phi \qty( \frac{x-\mu}{\sigma}) \end{equation}
We can’t integrate \(\Phi\) further. So we leave it as a special function.
And its expectations:
\(E(X) = \mu\)
\(Var(X) = \sigma^{2}\)
additional information
multi-variant Gaussian density
\begin{equation} z \sim \mathcal{N} \qty(\mu, \Sigma) \end{equation}
Generative Learning Algorithm
Last edited: October 10, 2025Gaussian Discriminant Analysis
High level idea: 1) fit parameters to the positive and negative examples separately as a multi-variant Gaussian density 2) try to see if a new samples’ probablitity to 1) is greater or 2) is greater.
requirements
- fit a parameter to
additional information
multivariant gaussian
See multi-variant Gaussian density. If it helps, here you go:
\begin{equation} p\qty(z) = \frac{1}{\qty(2\pi)^{\frac{|z|}{2}}|\Sigma|^{\frac{1}{2}}} \exp \qty(-\frac{1}{2} \qty(x-\mu)^{T} \Sigma^{-1} \qty(x - \mu)) \end{equation}
making predictions
Suppose \(p\qty(y=1) = \phi\), \(p\qty(y=0) = 1-\phi\).