Bernoulli distribution
Last edited: August 8, 2025Consider a case where there’s only a single binary outcome:
- “success”, with probability \(p\)
- “failure”, with probability \(1-p\)
constituents
\begin{equation} X \sim Bern(p) \end{equation}
requirements
the probability mass function:
\begin{equation} P(X=k) = \begin{cases} p,\ if\ k=1\\ 1-p,\ if\ k=0\\ \end{cases} \end{equation}
This is sadly not Differentiable, which is sad for Maximum Likelihood Parameter Learning. Therefore, we write:
\begin{equation} P(X=k) = p^{k} (1-p)^{1-k} \end{equation}
Which emulates the behavior of your function at \(0\) and \(1\) and we kinda don’t care any other place.
Bessel's Equation
Last edited: August 8, 2025\begin{equation} x^{2}y’’ + xy’ + (x^{2}-n^{2})y = 0 \end{equation}
this function is very useful, they have no well defined elementary result.
best-action worst-state
Last edited: August 8, 2025best-action worst-state is a lower bound for alpha vectors:
\begin{equation} r_{baws} = \max_{a} \sum_{k=1}^{\infty} \gamma^{k-1} \min_{s}R(s,a) \end{equation}
The alpha vector corresponding to this system would be the same \(r_{baws}\) at each slot.
which should give us the highest possible reward possible given we always pick the most optimal actions while being stuck in the worst state
BetaZero
Last edited: August 8, 2025Background
recall AlphaZero
- Selection (UCB 1, or DTW, etc.)
- Expansion (generate possible belief notes)
- Simulation (if its a brand new node, Rollout, etc.)
- Backpropegation (backpropegate your values up)
Key Idea
Remove the need for heuristics for MCTS—removing inductive bias
Approach
We keep the ol’ neural network:
\begin{equation} f_{\theta}(b_{t}) = (p_{t}, v_{t}) \end{equation}
Policy Evaluation
Do \(n\) episodes of MCTS, then use cross entropy to improve \(f\)
Ground truth policy
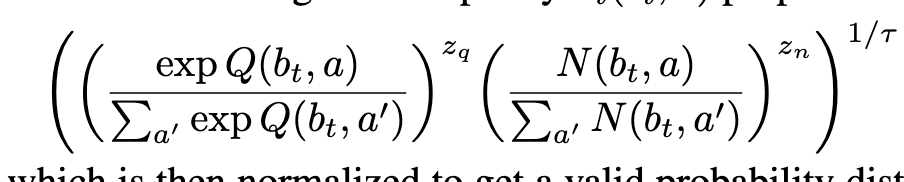
Action Selection
Beyond Worst-Case Analysis
Last edited: August 8, 2025There is no polynomial time algorithm \(A\) such that for all 3CNF \(\varphi\), \(A\qty(\varphi)\) accepts if and only if \(\varphi\) is satisfiable.
How do we relax this?
- we can say “for most” 3CNF formulas, which means that we have to name a distribution
- we can say to satisfy “most” \(\varphi\), meaning we can satisfy most clauses of \(\varphi\)
- allow more than poly-time (SoTA is at \(1.34\dots^{n}\)).
PCP Theorem
\(P \neq NP\) implies no polynomial time algorithm that finds \(x\) that satisfies \(99.9\%\) of clauses. In particular, no polytime algorithm that finds \(x\) that satisfies \(\geq \frac{7}{8} + \varepsilon\) fraction of the clauses.