Antonsson 2021
Last edited: August 8, 2025DOI: 10.3389/fnagi.2020.607449
One-Liner
oral lexical retrieval works better than qualitative narrative analysis to classify dementia; and semantic fluency + Disfluency features chucked on an SVM returns pretty good results.
Novelty
Tried two different assays of measuring linguistic ability: oral lexical retrieval metrics, and qualitative discourse features analysis of speech.
Notable Methods
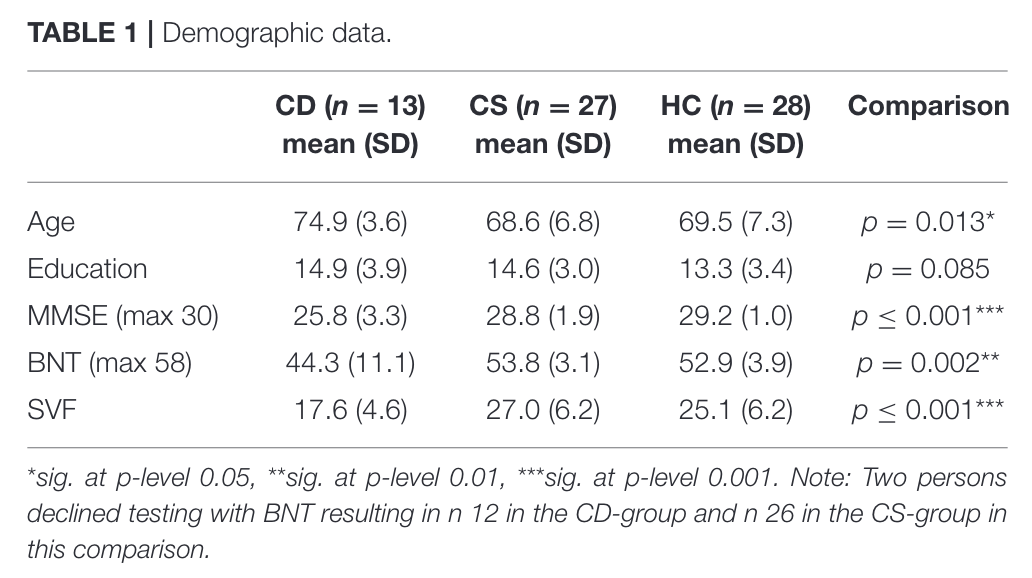
Subjects divided into three groups
- Great cog. decline
- Impaired but stable
- Healthy controls
Administered BNT and SVF tests as baseline
Key Figs
Table 3
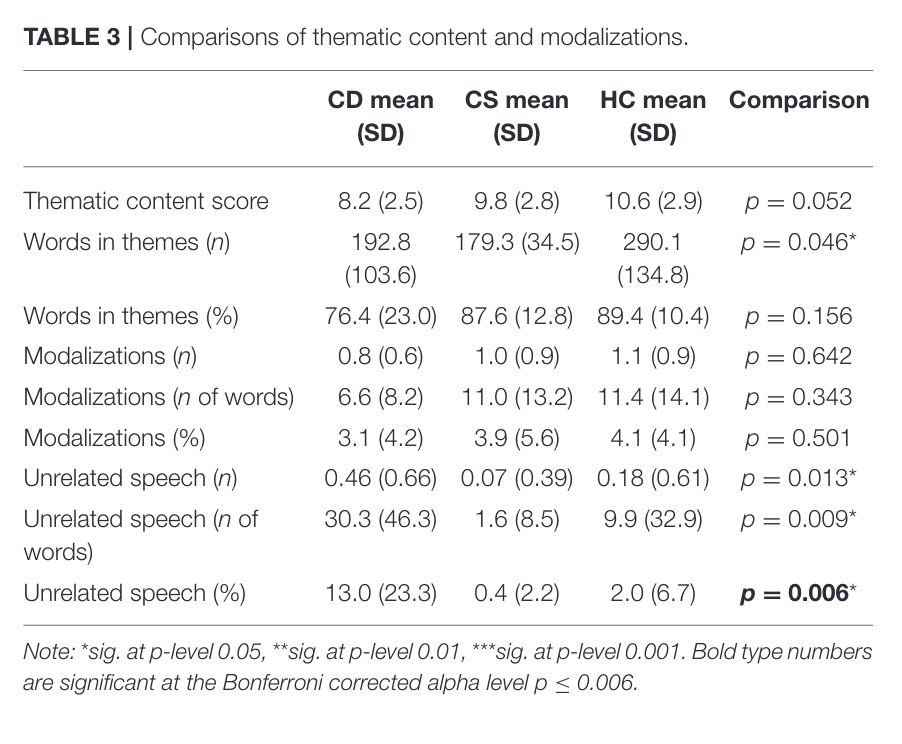
This figure tells us that the percentages of unrelated utterances was a statistically significant metric to figure differences between the three experimental groups.
Balagopalan 2021
Last edited: August 8, 2025DOI: 10.3389/fnagi.2021.635945
One-Liner
extracted lexicographic and syntactical features from ADReSS Challenge data and trained it on various models, with BERT performing the best.
Novelty
???????
Seems like results here are a strict subset of Zhu 2021. Same sets of dataprep of Antonsson 2021 but trained on a BERT now. Seem to do worse than Antonsson 2021 too.
Notable Methods
Essentially Antonsson 2021
- Also performed MMSE score regression.
Key Figs
Table 7 training result
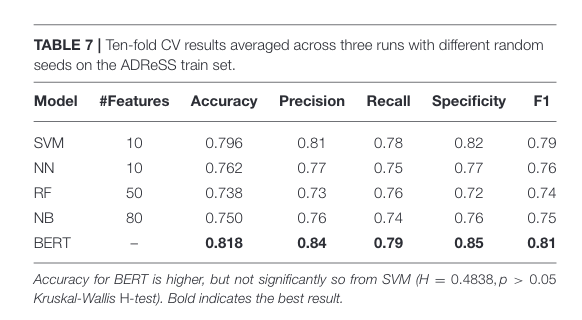
This figure shows us that the results attained by training on extracted feature is past the state-of-the-art at the time.
Chlasta 2021
Last edited: August 8, 2025DOI: 10.3389/fpsyg.2020.623237
One-Liner (thrice)
- Used features extracted by VGGish from raw acoustic audio against a SVM, Perceptron, 1NN; got \(59.1\%\) classif. accuracy for dementia
- Then, trained a CNN on raw wave-forms and got \(63.6\%\) accuracy
- Then, they fine-tuned a VGGish on the raw wave-forms and didn’t report their results and just said “we discovered that audio transfer learning with a pretrained VGGish feature extractor performs better” Gah!
Novelty
Threw the kitchen sink to process only raw acoustic input, most of it missed; wanted 0 human involvement. It seems like last method is promising.
Guo 2021
Last edited: August 8, 2025DOI: 10.3389/fcomp.2021.642517
One-Liner
Used WLS data to augment CTP from ADReSS Challenge and trained it on a BERT with good results.
Novelty
- Used WLS data with CTP task to augment ADReSS DementiaBank data
Notable Methods
WLS data is not labeled, so authors used Semantic Verbal Fluency tests that come with WLS to make a presumed conservative diagnoses. Therefore, control data is more interesting:
Key Figs
Table 2
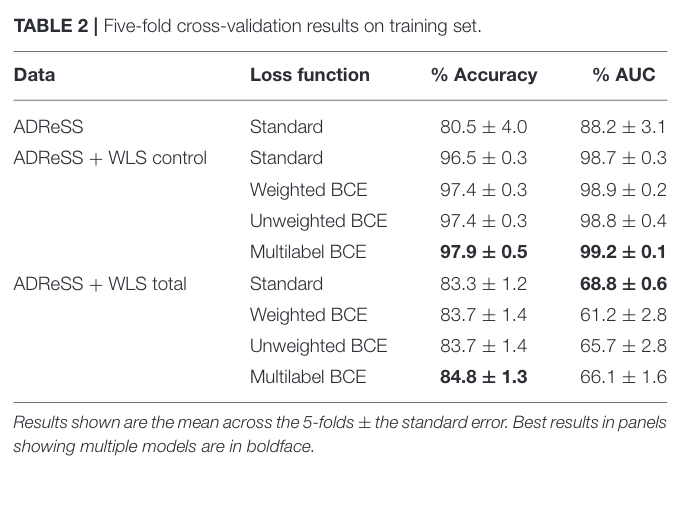
Data-aug of ADReSS Challenge data with WSL controls (no presumed AD) trained with a BERT. As expected the conservative control data results in better ferf
Jonell 2021
Last edited: August 8, 2025DOI: 10.3389/fcomp.2021.642633
One-Liner
Developed a kitchen sink of diagnoses tools and correlated it with biomarkers.
Novelty
The kitchen sink of data collection (phones, tablet, eye tracker, microphone, wristband) and the kitchen sink of noninvasive data imaging, psych, speech assesment, clinical metadata.
Notable Methods
Here’s their kitchen sink

I have no idea why a thermal camera is needed
Key Figs
Here are the features they extracted
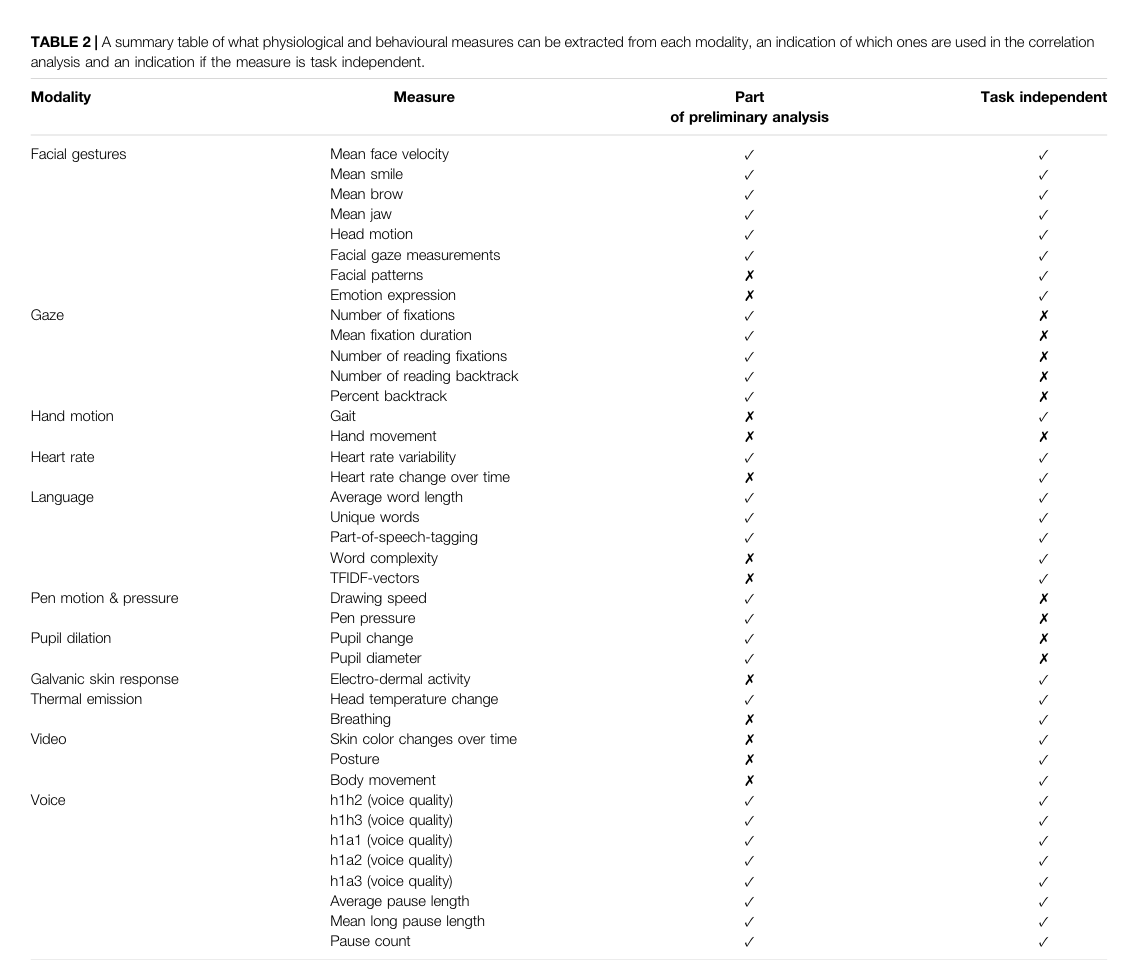
Developed the features collected via a method similar to action research, did two passes and refined/added information after preliminary analysis. Figure above also include info about whether or not the measurement was task specific.