Laguarta 2021
Last edited: August 8, 2025DOI: 10.3389/fcomp.2021.624694
One-Liner
Proposed a large multimodal approach to embed auditory info + biomarkers for baseline classification.
Novelty
Developed a massively multimodal audio-to-embedding correlation system that maps audio to biomarker information collected (mood, memory, respiratory) and demonstrated its ability to discriminate cough results for COVID. (they were looking for AD; whoopsies)
Notable Methods
- Developed a feature extraction model for AD detection named Open Voice Brain Model
- Collected a dataset on people coughing and correlated it with biomarkers
Key Figs
Figure 2
This is MULTI-MODAL as heck
Lindsay 2021
Last edited: August 8, 2025DOI: 10.3389/fnagi.2021.642033
One-Liner
Proposed cross-linguistic markers shared for AD patients between English and French; evaluated features found with standard ML.
Novelty
Multi-lingual, cross-linguistic analysis.
Notable Methods
Key Figs
Figure 1
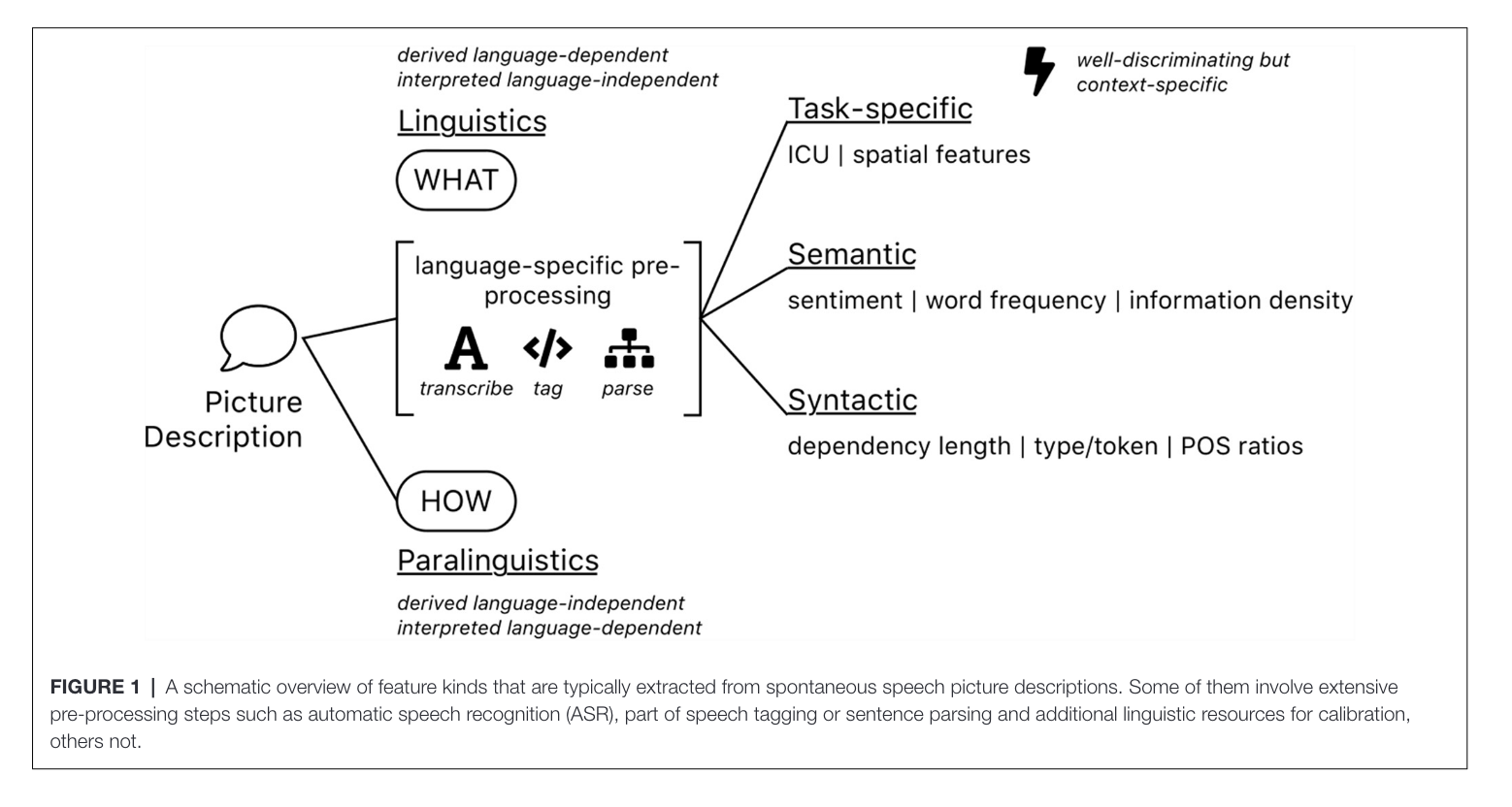
This figure tells us the various approaches measured.
Table 2
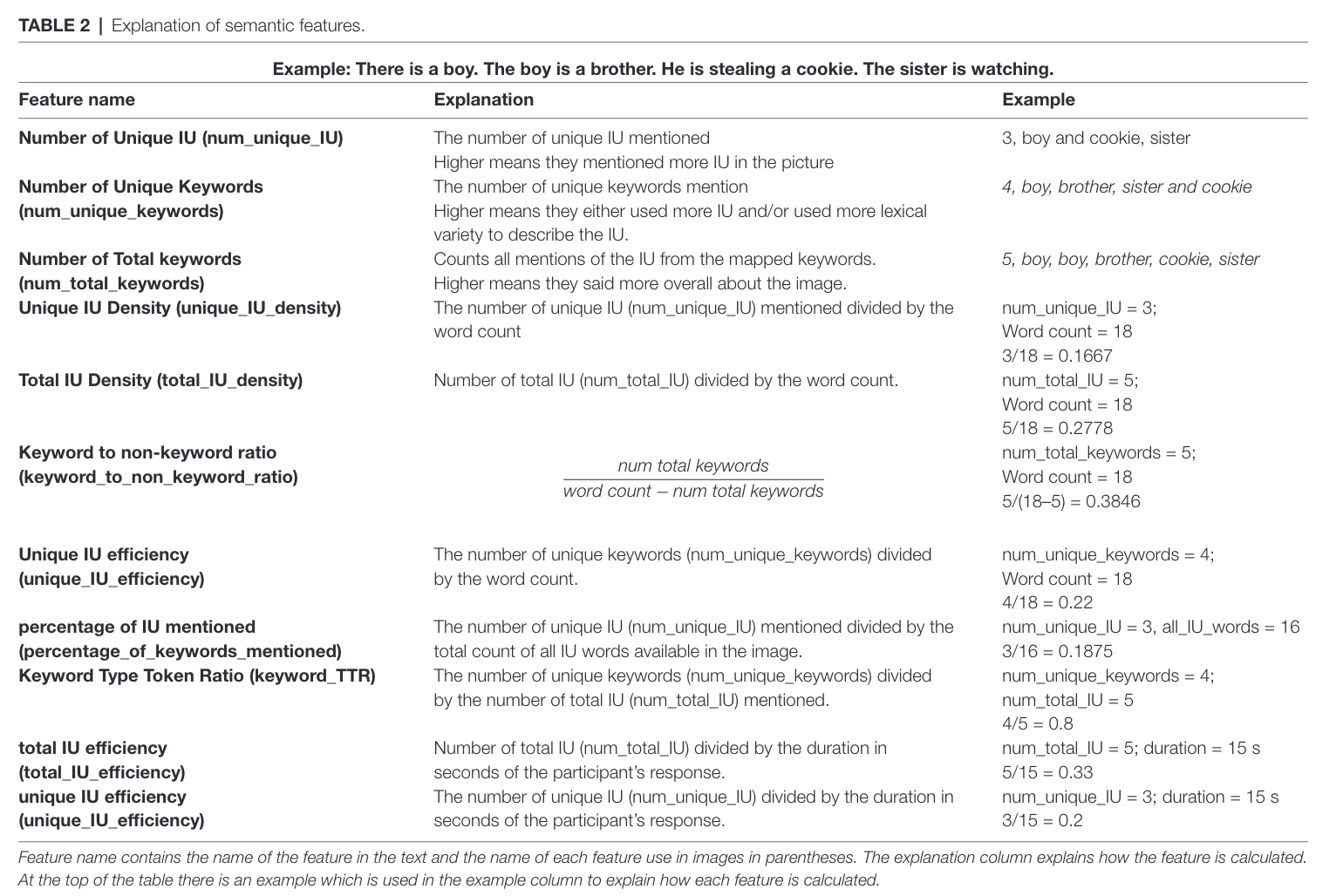
Here’s a list of semantic features extracted
Table 3
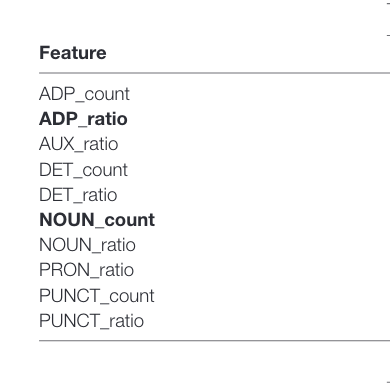
Here’s a list of NLP features extracted. Bolded items represent P <0.001 correlation for AD/NonAD difference between English and French.
Luz 2021
Last edited: August 8, 2025DOI: 10.1101/2021.03.24.21254263
One-Liner
Review paper presenting the \(ADReSS_o\) challenge and current baselines for three tasks
Notes
Three tasks + state of the art:
- Classification of AD: accuracy \(78.87\%\)
- Prediction of MMSE score: RMSE \(5.28\)
- Prediction of cognitive decline: accuracy \(68.75\%\)
Task 1
AD classification baseline established by decision tree with late fusion
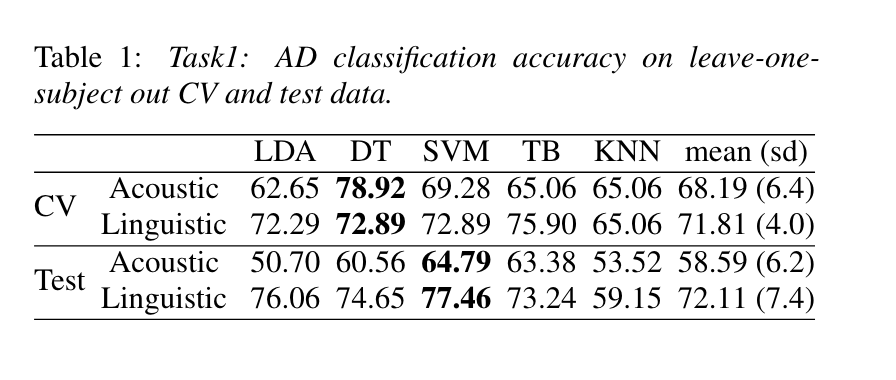
(LOOCV and test)
Task 2
MMSE score prediction baseline established by grid search on parameters.
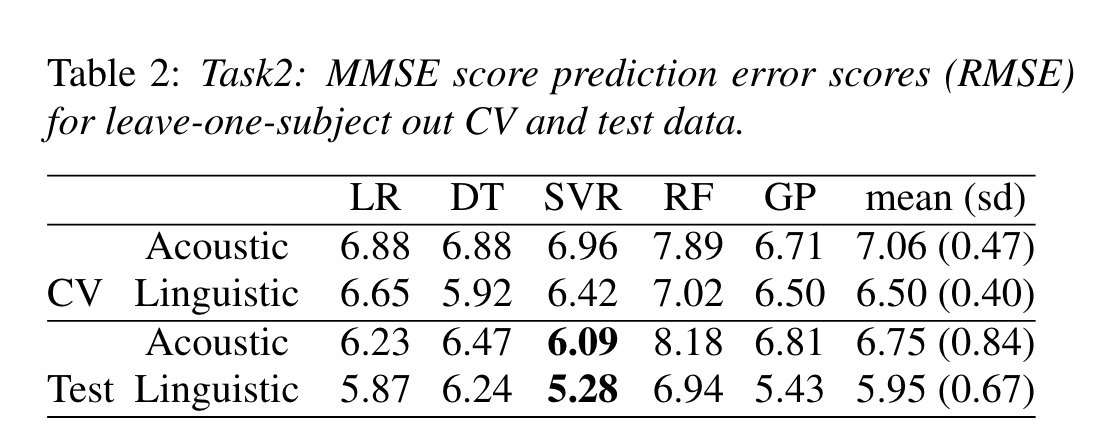
SVR did best on both counts; results from either model are averaged for prediction.
Mahajan 2021
Last edited: August 8, 2025DOI: 10.3389/fnagi.2021.623607
One-Liner
Trained a bimodal model on speech/text with GRU on speech and CNN-LSTM on text.
Novelty
- A post-2019 NLP paper that doesn’t use transformers! (so
faster(they used CNN-LSTM) lighter easier) - “Our work sheds light on why the accuracy of these models drops to 72.92% on the ADReSS dataset, whereas, they gave state of the art results on the DementiaBank dataset.”
Notable Methods
Bi-Modal audio and transcript processing vis a vi Shah 2021, but with a CNN-LSTM and GRU on the other side.
Martinc 2021
Last edited: August 8, 2025DOI: 10.3389/fnagi.2021.642647
One-Liner
Combined bag-of-words on transcript + ADR on audio to various classifiers for AD; ablated BERT’s decesion space for attention to make more easy models in the future.
Novelty
- Pre-processed each of the two modalities before fusing it (late fusion)
- Archieved \(93.75\%\) accuracy on AD detection
- The data being forced-aligned and fed with late fusion allows one to see what sounds/words the BERT model was focusing on by just focusing on the attention on the words
Notable Methods
- Used classic cookie theft data
- bag of words to do ADR but for words
- multimodality but late fusion with one (hot-swappable) classifier
Key Figs
How they did it
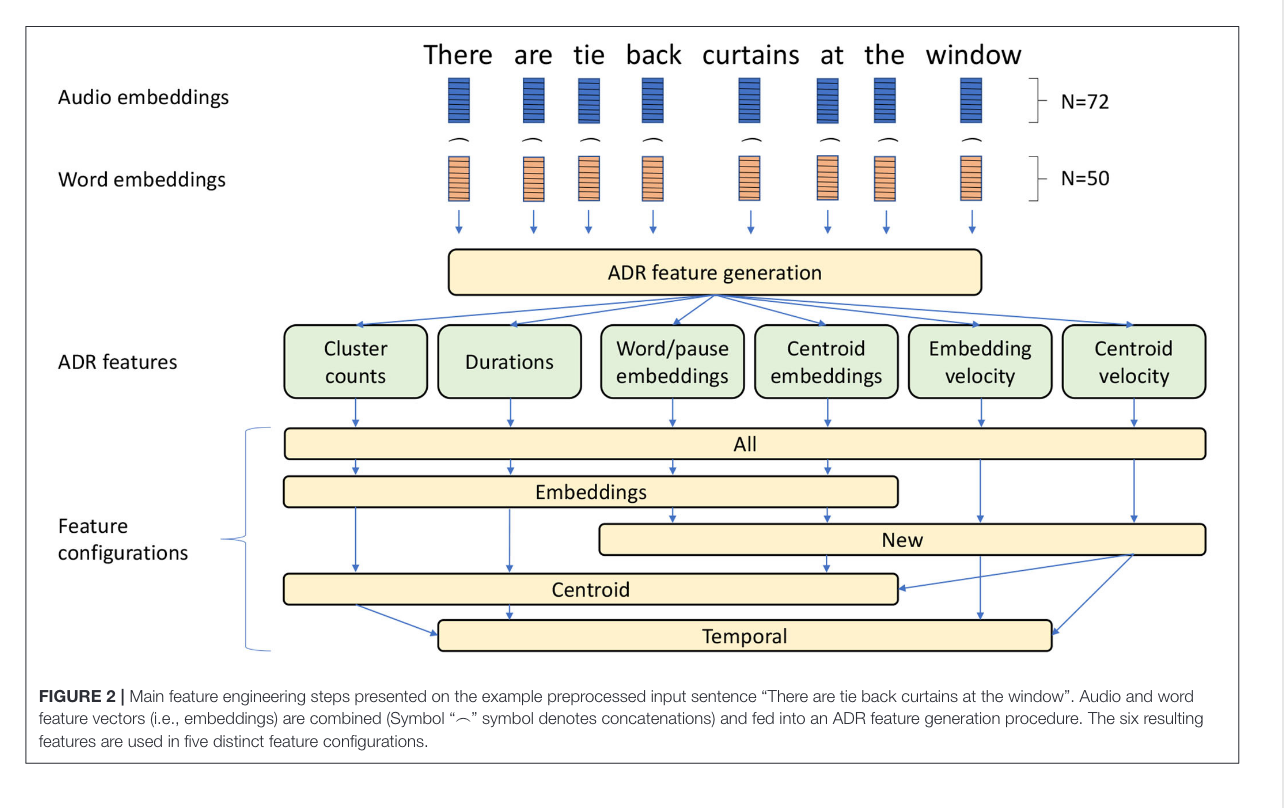
This is how the combined the forced aligned (:tada:) audio and transcript together.